...

Athena로 ALB Access Log 추출하기
지난 시간에 ALB (Application Load Balancer: 애플리케이션 로드 밸런서) 의 access log를 활성화 하고, s3에 저장토록 설정했었다.
하지만 로그 파일들을 이용하는데 있어 매우 불편한점이 한두가지가 아니었는데,
첫번째는 ALB 로그는 모든 요청 로그를 남기기 때문에 로그를 수백/수천개의 압축파일로 생성해서 버킷에 몽땅 저장한다는 점이다. 서비스의 트래픽이 얼마나 많으냐에 따라 다르겠지만, 대량의 트래픽이 발생하는 경우 1시간에도 수백/수천개의 gz 파일이 생성되기도 한다.
두번째는 로그 파일 내용물이 가독성이 매우 안좋다는 점이다. 로그를 뒤져서 이상한 트래픽을 걸러내야 하는데, 이렇게 사람이 읽기 어려운 형태로 문자들이 나열되어 있으면 아무래도 생산성이 많이 낮아진다. 또한 로그 파일 하나 읽으려면 일일히 압축을 풀어야 한다는 점도 역시 걸리적 거린다.
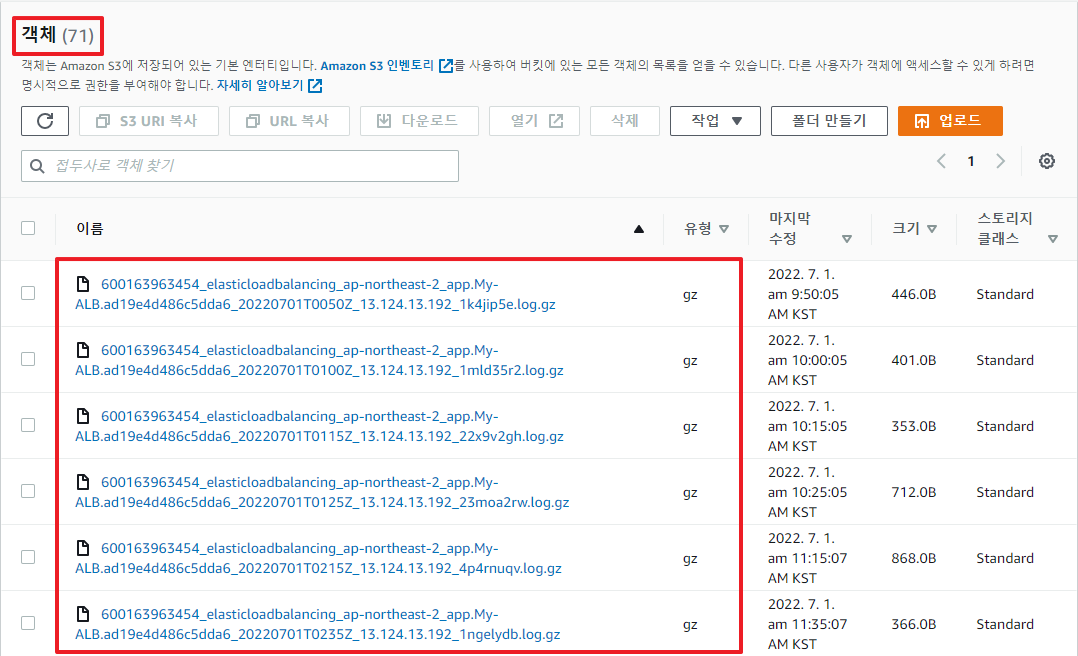
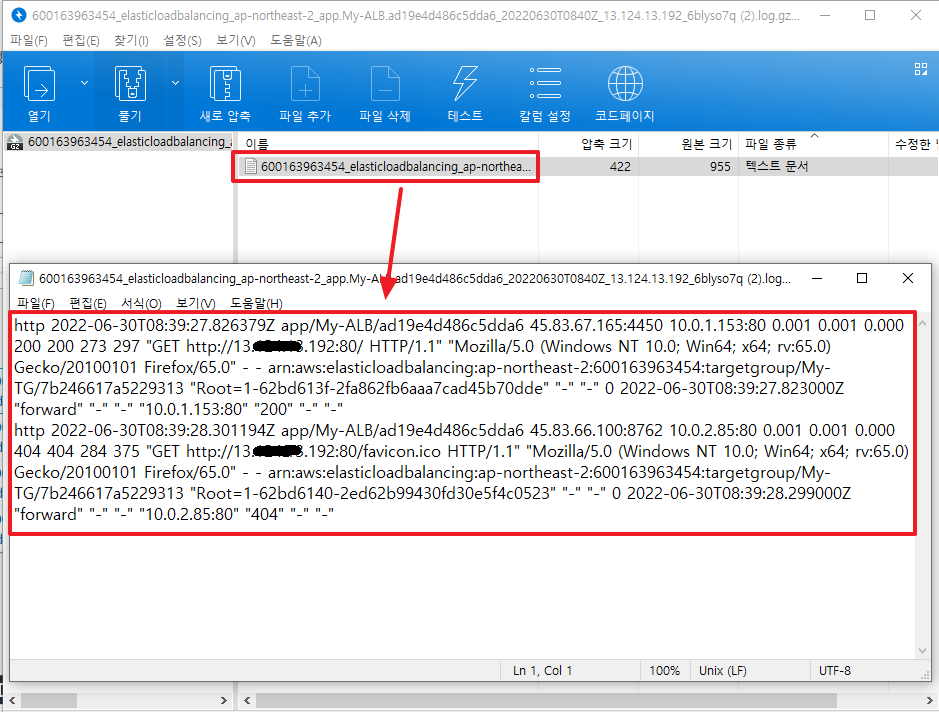
따라서 이 읽기도 어렵고 다루기도 어려운 ALB access log를 Athena 서비스를 이용하여 보기좋게 가독성 좋게 만들고, 또한 SQL문으로 로그 데이터를 쿼리하여 원하는 데이터를 빠르게 추출할수 있도록 설정해보자.
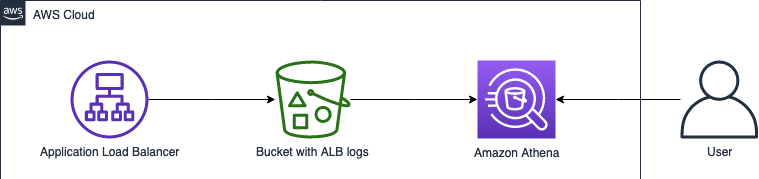
AWS Athena는 S3에 저장된 log 파일들을 데이터베이스(테이블)화 하여, SQL로 로그를 조회할 수 있게 하는 서비스이다.
만일 Athena의 전반적인 사용법에 대해서 잘 모른다면 다음 포스팅을 참고하길 바란다.
[AWS] 📚 Athena 사용법 정리 (S3에 저장된 로그 쿼리하기)
AWS Athena 서비스 S3 Athena는 S3에 저장된 데이터를 SQL 언어로 조회할 수 있는 대화식 서비스이다. 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 간편하게 분석할 수 있고 몇 초 안에 대용량을 데이
inpa.tistory.com
Athena Access log 테이블 만들기
테이블 생성에 앞서 먼저 alb 로그를 다루는 전용 데이터베이스를 생성해보자.
CREATE DATABASE ALB_LOG_DB;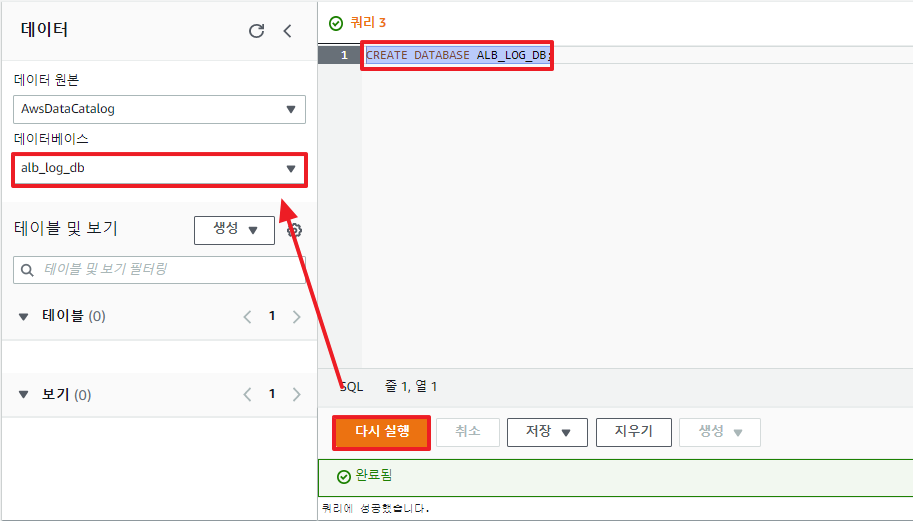
데이터베이스를 생성하였으면, ALB Access Log의 포맷에 맞게 컬럼을 지정해주고 테이블을 생성해준다.
현재 ALB Access Log 파일이 저장되어 있는 버킷 경로 형식은 다음과 같이 되어있다.
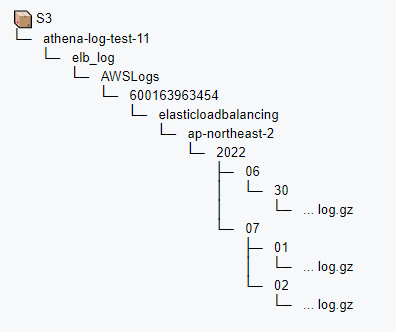
alb access log 자체 기능에서 로그 파일을 저장할때 위와 같이 년도, 월별, 날짜 별로 버킷 폴더를 나누어 저장됨을 볼수 있다.
이 S3 버킷 경로 형식에 맞춰서 테이블을 만들 것이다.
단, ALB Access Log 는 앞으로도 지속적으로 버킷에 로그 파일이 쌓일것이니 데이터 파티셔닝 이 중요하다.
파티셔닝을 하지않으면 풀스캔이 되고 스캔한 데이터에 알맞게 요금이 매우 많이 들기 때문이다.
다음은 Projectrion Partitiong 기능을 사용하여 파티션 테이블을 만드는 쿼리이다.
데이터 파티셔닝과 프로젝션 파티셔닝에 대해서는 위 텍스트 링크의 포스팅을 참고하길 바란다.
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs_partition_projection (
type string,
TIME string,
elb string,
client_ip string,
client_port INT,
target_ip string,
target_port INT,
request_processing_time DOUBLE,
target_processing_time DOUBLE,
response_processing_time DOUBLE,
elb_status_code string,
target_status_code string,
received_bytes BIGINT,
sent_bytes BIGINT,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
PARTITIONED BY(YEAR INT, MONTH INT, DAY INT) -- 파티션 컬럼
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"'
)
LOCATION 's3://athena-log-test-11/elb_log/AWSLogs/600163963454/elasticloadbalancing/ap-northeast-2/' -- 로그 파일이 있는 경로
TBLPROPERTIES (
'projection.enabled' = 'true', -- projection 사용하기
'projection.day.digits' = '2', -- 일짜를 01, 02, 03 형식으로 사용
'projection.day.range' = '01,31', -- 01일에서 31일 까지
'projection.day.type' = 'integer', -- int 타입
'projection.month.digits' = '2', -- 월별을 01, 02, 03 형식으로 사용
'projection.month.range' = '01,12', -- 01월에서 12월 까지
'projection.month.type' = 'integer', -- int 타입
'projection.year.digits' = '4', -- 년도를 4글자로 사용
'projection.year.range' = '2021,2023', -- 2021 ~ 2023 까지 스캔
'projection.year.type' = 'integer', -- int 타입
"storage.location.template" = "s3://athena-log-test-11/elb_log/AWSLogs/600163963454/elasticloadbalancing/ap-northeast-2/${year}/${month}/${day}" -- 경로 형식
)쿼리가 잘 안되면 주석을 지우고 실행해 보자.
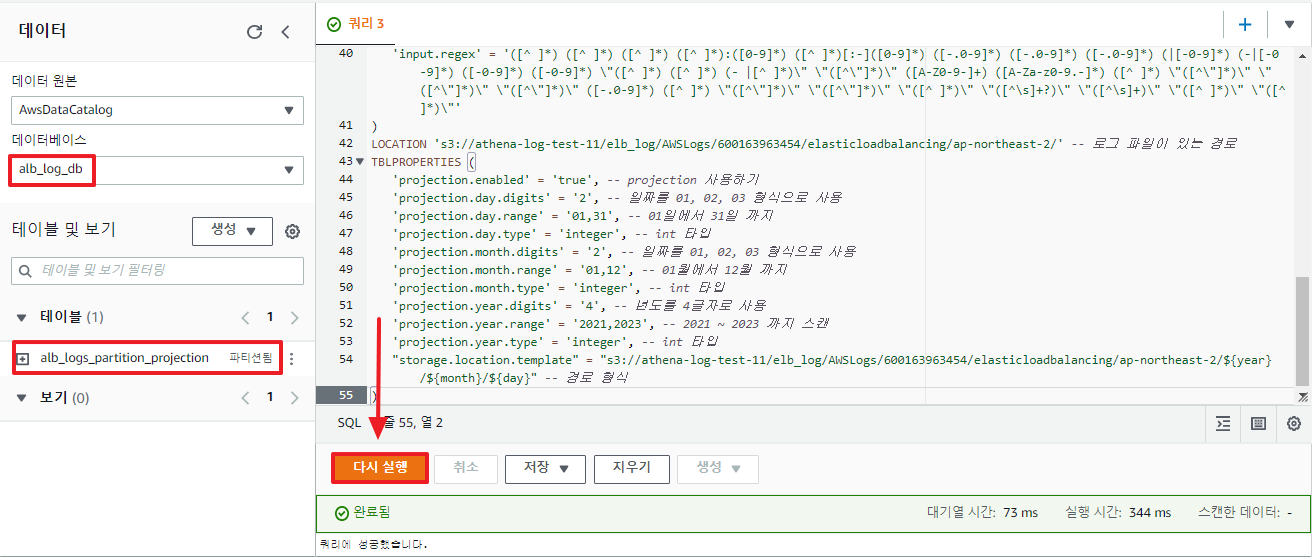
오류 없이 테이블이 무사히 생성되었다. 이제 한번 로그를 조회해 보자.
만일 6월 30일 달의 폴더에 있는 로그들만 조회하고 싶다면 다음과 같이 질의를 날리면 된다.
SELECT * FROM "alb_log_db"."alb_logs_partition_projection" where month=06 and day=30;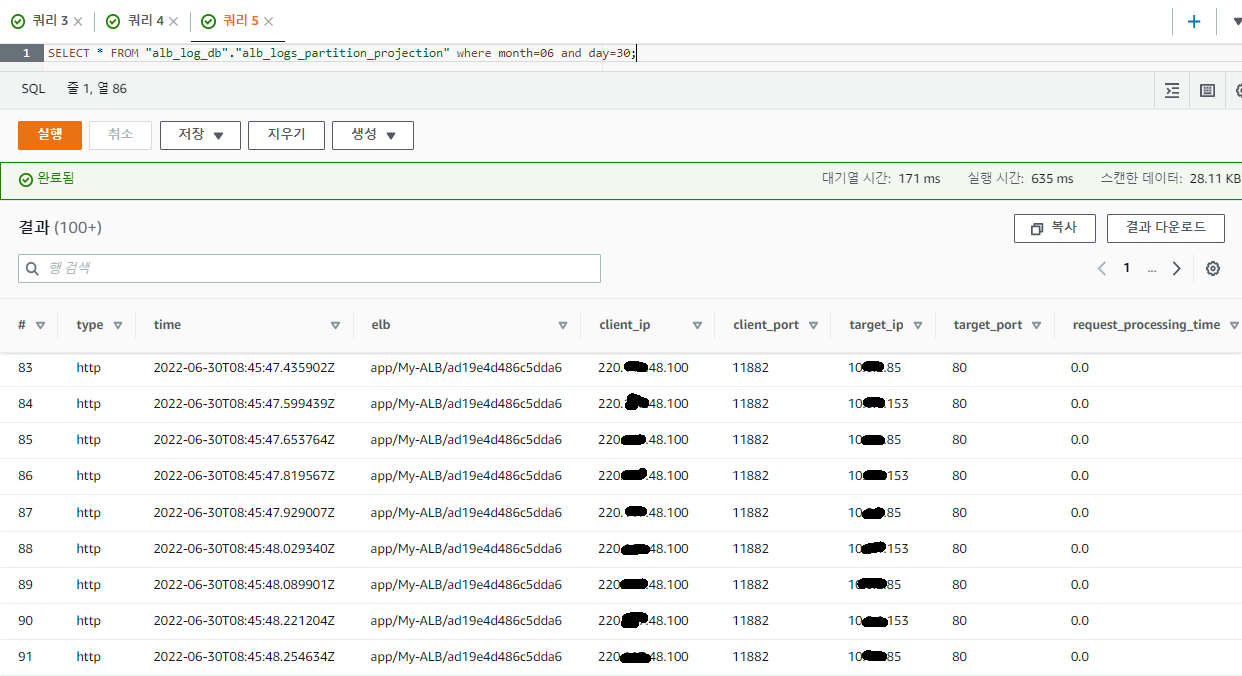
이처럼, SQL문으로 특정 날짜나 특정 아이피, 포트를 걸러 재빠르게 로그를 조회해 트래픽을 관리할 수가 있다.
Athena Access log 분석하기
최근의 요청 100건
SELECT * FROM 테이블명
ORDER by time DESC LIMIT 100;
웹 로딩 시간 분석하기
2022.07.01 ~ 2022.07.04까지 5초이상 수행된 URL 사이트와 로딩 시간 출력
SELECT time, url
from 테이블명
WHERE parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') >= parse_datetime('2022-07-01-00:00:00','yyyy-MM-dd-HH:mm:ss')
AND parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') < parse_datetime('2022-07-03-00:00:00','yyyy-MM-dd-HH:mm:ss')
AND (time >= 5.0)
호출 건수 분석하기
2022.07.01(하루) 동안 www.tistory.com 으로 호출 건수 출력
SELECT count(1)
FROM 테이블명
WHERE url LIKE '%www.tistory.com%'
AND parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') >= parse_datetime('2020-07-01-00:00:00','yyyy-MM-dd-HH:mm:ss')
AND parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') < parse_datetime('2020-07-02-00:00:00','yyyy-MM-dd-HH:mm:ss');
이외에도 다양한 사례가 궁금하면 AWS 공식 문서를 참고해보자.
Athena를 사용하여 로드 밸런서 로그 분석
기본적으로 Elastic Load Balancing은 액세스 로깅을 활성화하지 않습니다. 액세스 로깅을 활성화할 때 Amazon Simple Storage Service(Amazon S3) 버킷을 지정합니다. 모든 Application Load Balancer 및 Classic Load Balancer
aws.amazon.com
이 글이 좋으셨다면 구독 & 좋아요
여러분의 구독과 좋아요는
저자에게 큰 힘이 됩니다.


