...

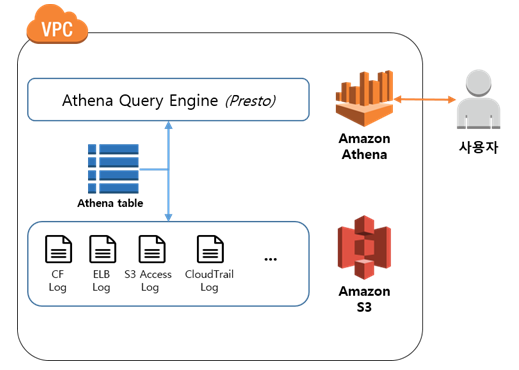
AWS Athena 서비스
S3 Athena는 S3에 저장된 데이터를 SQL 언어로 조회할 수 있는 대화식 서비스이다.
표준 SQL을 사용해 Amazon S3에 저장된 데이터를 간편하게 분석할 수 있고 몇 초 안에 대용량을 데이터를 조회해 검색 결과를 얻을 수 있다.
보통 로그같은 대규모 데이터는 EBS나 ElasticSearch 등에 적재하기에는 많은 비용이 발생하기 때문에, S3와 같은 저렴한 스토리지에 저장하게 된다.
하지만 로그를 가져올 때 조건을 거는 부분과 많은 양의 압축된 로그 파일을 로드하고 압축을 푸는데 시간이 너무 많이 소요되는 문제가 생긴다.
따라서 이러한 문제들을 해결해줄수 있는 서비스가 Athena(아테나)이다.
Athena(아테나)에 데이터가 저장되어있는 S3를 설정해주고 테이블 생성 후 쿼리를 실행하기만 하면 데이터를 가져올 수 있다. 파일을 로드하고 압축을 풀지 않아도 되고 SQL문을 통해 제약 조건 걸어 원하는 데이터만 가져올 수 있어서 조회하기도 편하고 빠르다.
Athena는 우선 S3의 버킷에 저장된 파일(log)들을 쭉 스캔하고, 사용자가 정의한 스키마 형태에 따라 파일 내용을 RDBMS 의 테이블 구조로 변환한다.
그렇게 S3에 적재되어 있는 데이터의 스키마만 테이블처럼 정의해 두면, 나중에 버킷에 파일이 추가되도 아테나가 자동으로 데이터베이스 처리 해줘서, 압축 풀거나 할거 없니 표준 SQL로 이들을 쿼리만 하면 되는 것이다.
또한 Athena는 Serverless 서비스이므로 관리할 인프라가 없으며 Lambda(람다)와 같이 실행한 쿼리에 대해서만 비용을 지불하면 되는 장점을 지니고 있다.
다만 쿼리할 데이터 크기가 클수록 스캔 비용이 늘어나므로, 스캔한 데이터의 사이즈를 최소화 하기 위해서 데이터 압축, 파티션, 열 기반 데이터 형식 등이 중요하다.
Athena 비용은 S3에서 스캔하는 데이터 1TB당 5 달러이다.
정리하자면 Athena 서비스에 대한 특징은 다음과 같다.
- 별다른 설치 없이 AWS Console에 접속하여 편리하게 사용
- 쿼리를 병렬로 실행하여 대규모 데이터 집합과 복잡한 쿼리에서도 빠르게 결과를 얻을 수 있음
- Amazon S3에 있는 데이터를 로딩하거나 변환시킬 필요 없이 직접 쿼리 실행 가능
- 데이터가 파티션 단위로 나뉘어 있기 때문에 실시간 조회는 불가능
- 관리해야 하는 클러스터, 설정하거나 관리할 인프라가 없는 서버리스 형태 (Serverless)
- Amazon Athena는 실행한 쿼리에 대한 비용만 지불. 각 쿼리에서 스캔한 데이터 양에 따라 요금 부과
- 테이블 생성을 위한 CREATE, 파티셔닝을 위한 ALTER 같은 DDL문, 실패한 쿼리문은 비용청구를 하지 않음
- 데이터를 압축 또는 파티셔닝하거나 컬럼 형식으로 변환하면 스캔해야 하는 데이터 양이 감소하므로 비용이 절감됨
AWS Athena 사용해보기
S3 로그 버킷 생성 및 로그 업로드

버킷을 생성하고 첨부된 csv 파일을 S3에 업로드 해보자.
time,user_id,board_name,action
2022-03-06 22:06,bob,game,insert
2022-03-05 22:06,jake,free,delete
2022-03-05 22:06,jake,stock,delete
2022-03-05 22:06,jake,free,insert
2022-03-05 22:06,bob,game,insert
2022-03-05 22:06,mike,qna,delete
2022-03-05 22:06,alica,qna,insert
2022-03-05 22:06,mike,game,delete
2022-03-05 22:06,mike,stock,view
2022-03-05 22:06,jake,qna,insert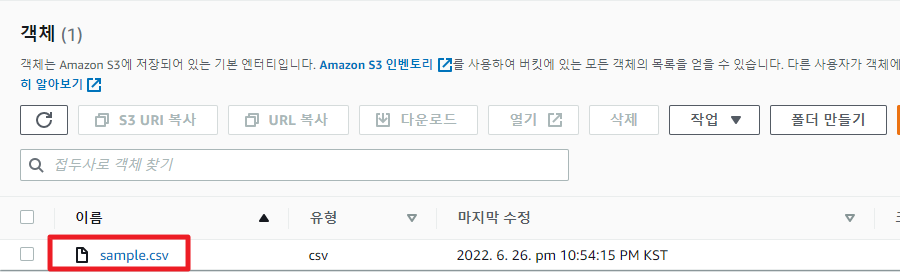
Athena에서 데이터베이스 및 테이블 생성
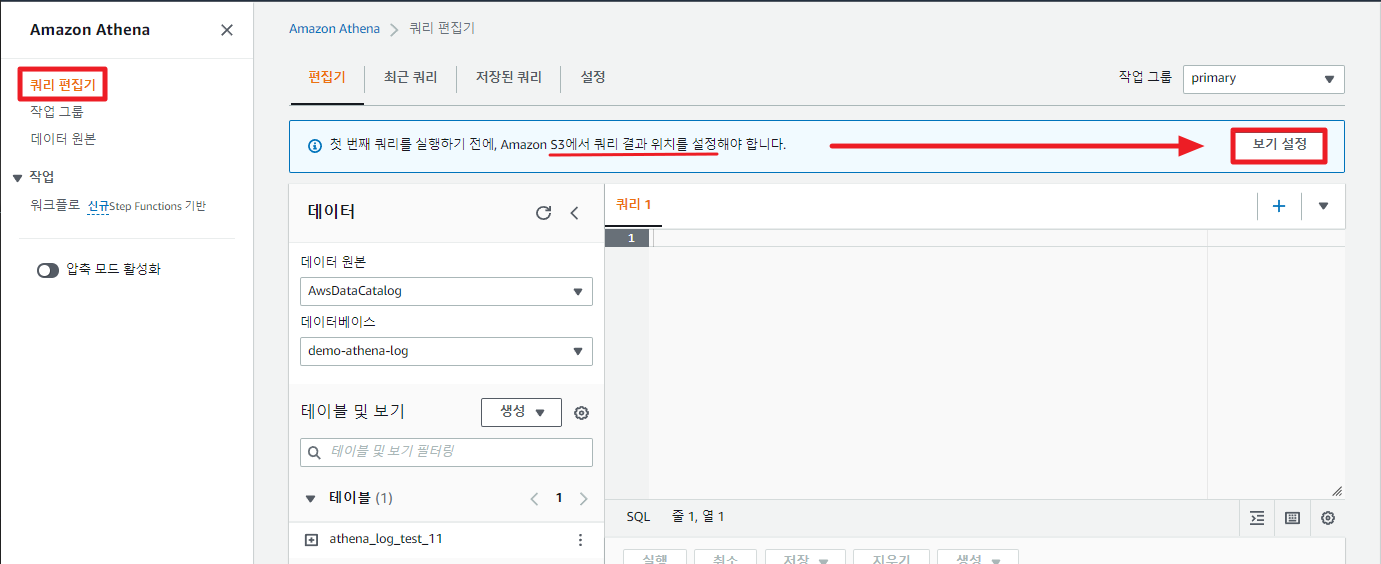
Athena 서비스 콘솔 메뉴로 들어와 쿼리 편집기에 들어가보자.
가장 먼저 쿼리 결과를 저장할 위치를 설정해주어야 한다. 우측에 보기 설정을 눌러 S3 경로를 설정해 주자.
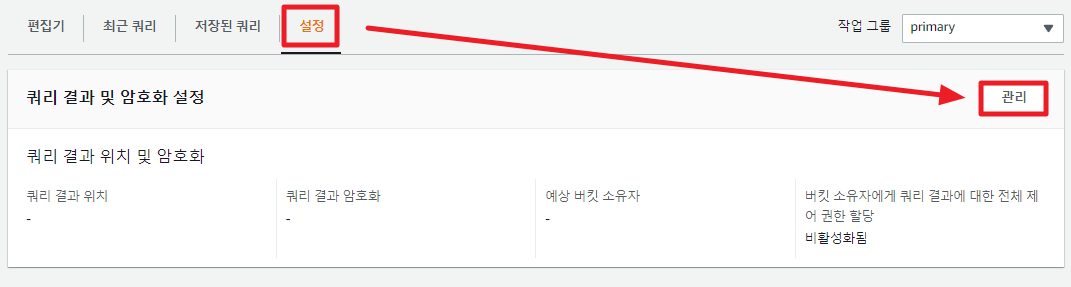
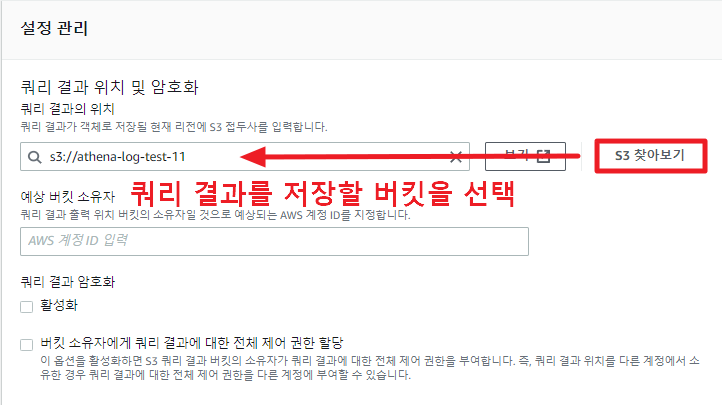
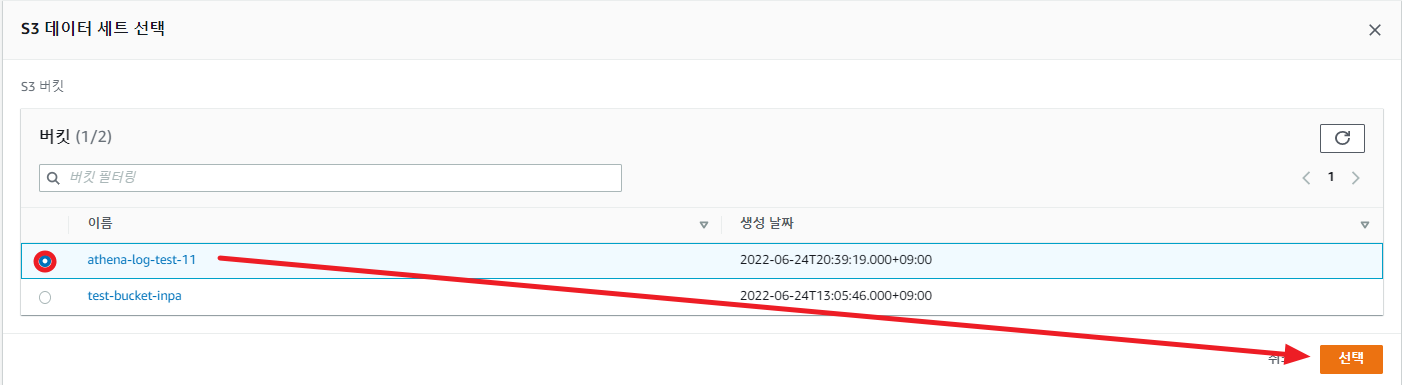
저장소 경로를 설정해주었으니, 이제 데이터베이스를 만들어주자.
아래의 SQL문을 쿼리 1 항목에 복사 붙여넣기하고 실행해보자.
CREATE DATABASE test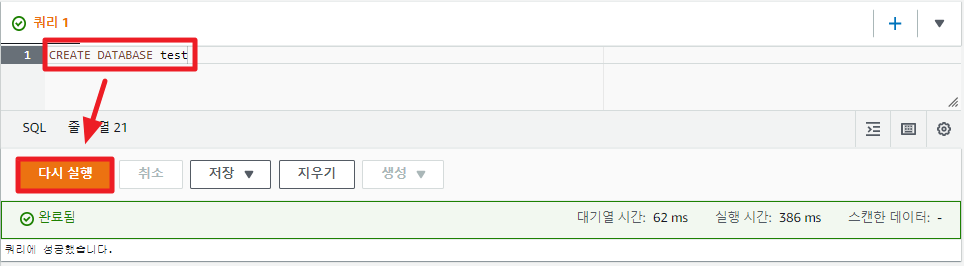
데이터베이스 생성에 성공 하면, 좌측 사이드바에서 데이터베이스 항목을 test db로 변경해준다.
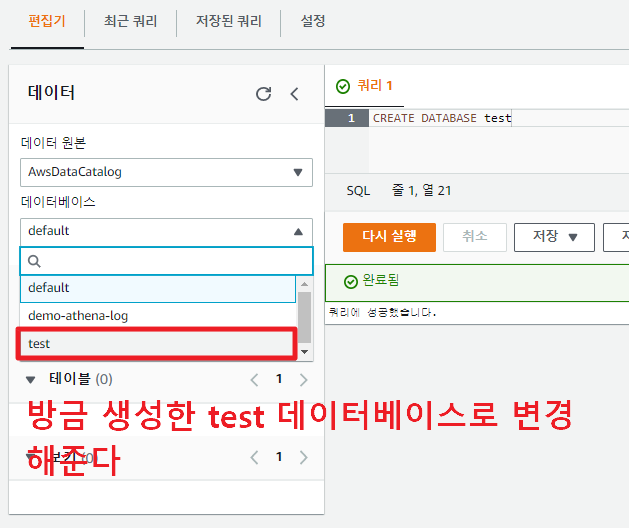
이제 테이블을 만들어보자. 다음 SQL문을 넣고 실행한다.
단, 쿼리 실행시 해당 버킷 디렉토리에 있는 모든 파일을 대상으로 하기 때문에 csv 데이터 파일 외에 다른 파일은 없어야 한다.
CREATE EXTERNAL TABLE IF NOT EXISTS mycsv (
`time` STRING,
`user_id` STRING,
`board_name` STRING,
`action` STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' -- 쉼표로 구분자
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://athena-log-test-11/' -- 파일명이 아닌 업로드 디렉토리 위치를 기재 !!
TBLPROPERTIES ("skip.header.line.count"="1"); -- 스키마 생성에서 첫번째 라인은 스킵한다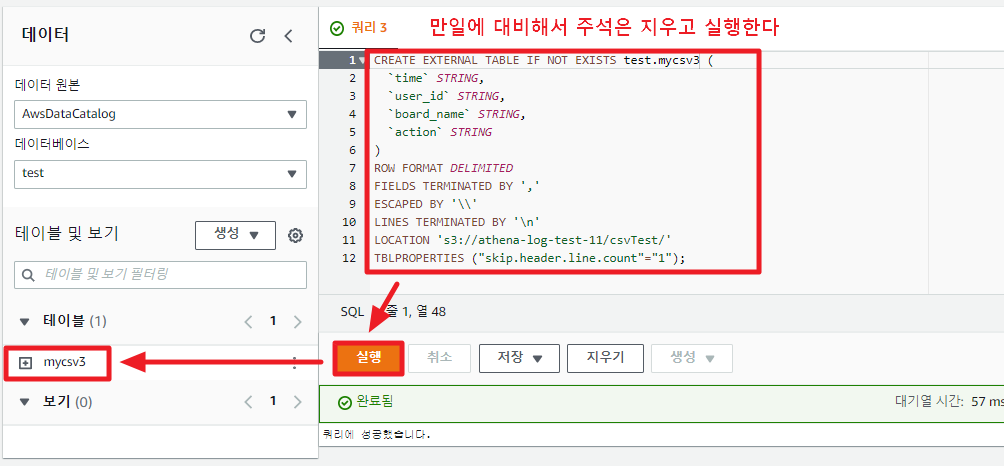
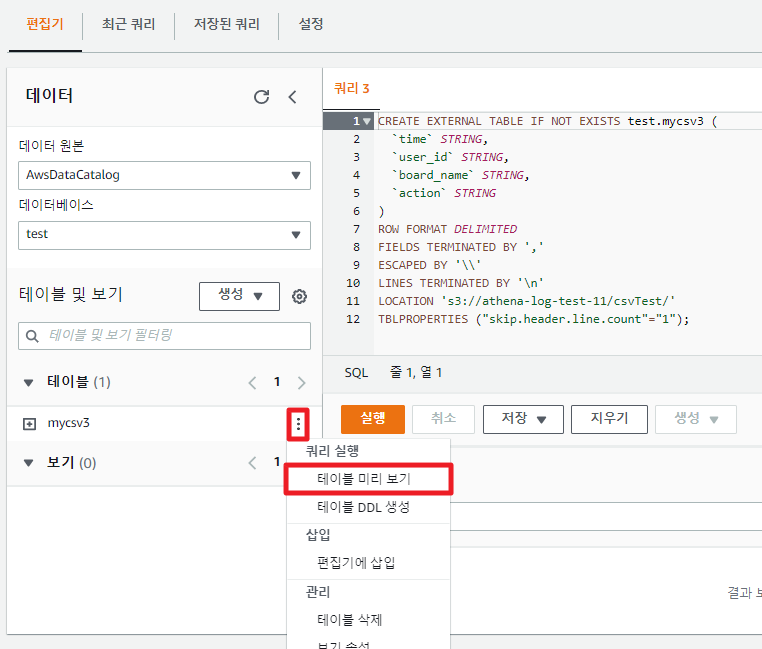
테이블 SELECT문을 실행해보자.
직접 쿼리창에 SELECT * FROM "test"."mycsv" limit 10; 쳐도 되지만 간편하게 메뉴를 지원한다.

이번엔 직접 조건 조회 쿼리문을 작성하여 실행해보자.
값을 지정할때 쌍따옴표 대신 작은따옴표를 써야 에러가 안생긴다.
SELECT * FROM "test"."mycsv" where user_id in('bob','jake');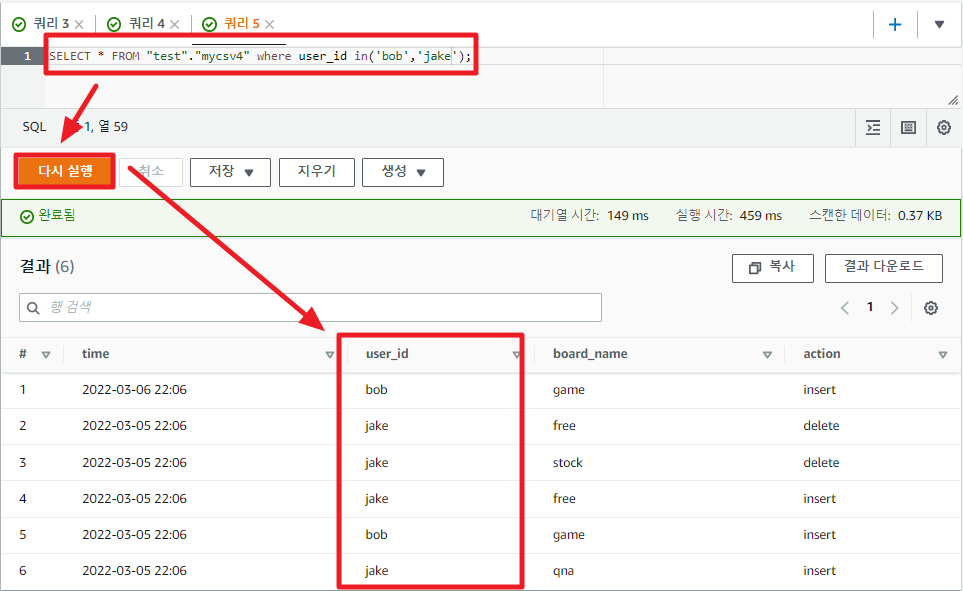
파일 추가 업로드
위에서 csv 파일로 데이터베이스와 테이블을 생성하여 쿼리 조회까지 해보았다.
그런데 만일 csv파일이 S3에 추가로 업로드 되었다고 하자.
AWS Athena에서 테이블을 만들때 S3 버킷경로를 이용해 만들었었는데, 그러면 새로 업로드 된 파일은 어떻게 처리될까?
위의 첨부파일을 열고 값을 일부 변경한 후 S3에 새로 업로드 해보자.
당연히 반드시 같은 버킷 경로에 넣어주어야 하고 같은 테이블 필드 포맷으로 구성되어 있어야 한다.
갑자기 뜬금없이 json이나 tsv 파일을 업로드하거나 전혀 다른 필드 형식의 csv 파일을 올리면 Athena 테이블이 깨져버릴수 있으니, S3에 파일 타입별로 폴더별로 관리하는것이 좋다.
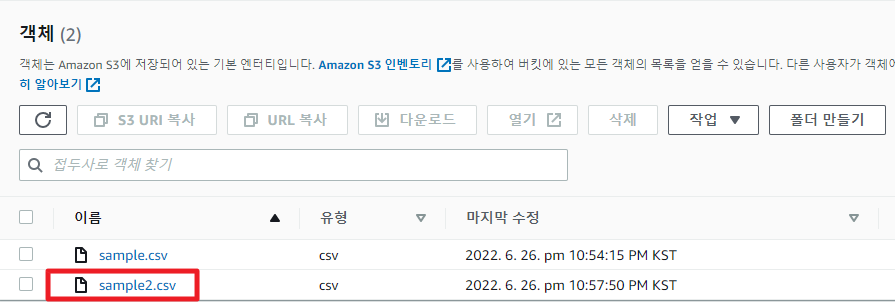
위의 sample.csv 파일의 라인수는 10개였다.
추가로 내용만 바꾼 sample2.csv를 추가했으니, 총 테이블의 레코드 수는 20개가 된다.
즉, 한번 버킷 경로에 테이블 포맷 등록을 해놓으면, 파일이 새로 추가가 되어도 자동으로 테이블로 변환되어 Athena에서 곧바로 사용할수 있는 것이다.
SELECT count(*) FROM "test"."mycsv";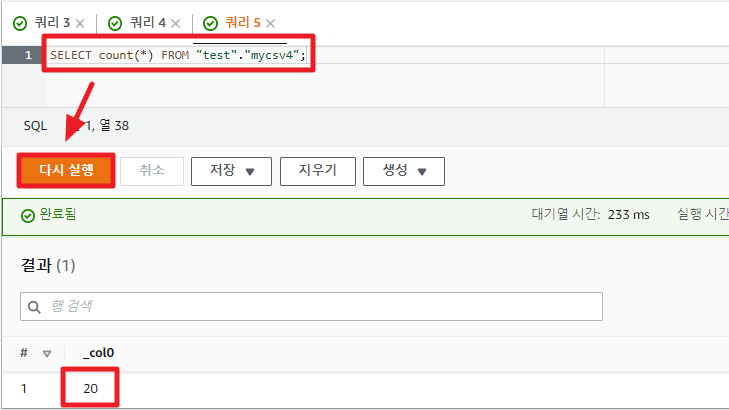
Athena JSON 데이터 형식
지금까지 csv 데이터 파일을 활용하여 테이블로 만들고 쿼리해 보았다.
이밖에 아테나는 CSV, TSV, JSON, 사용자 지정 구분 기호 등의 다양한 데이터 형식을 지원한다.
다음 JSON 데이터가 S3 버킷에 있다고 가정하자.
{"time":"2022-03-05 22:06:13","user_id":"bob","board_name":"game","action":"insert"}
{"time":"2022-03-05 22:06:14","user_id":"jake","board_name":"free","action":"delete"}
{"time":"2022-03-05 22:06:15","user_id":"jake","board_name":"stock","action":"delete"}
{"time":"2022-03-05 22:06:16","user_id":"jake","board_name":"free","action":"insert"}
{"time":"2022-03-05 22:06:17","user_id":"bob","board_name":"game","action":"insert"}
{"time":"2022-03-05 22:06:18","user_id":"mike","board_name":"qna","action":"delete"}
{"time":"2022-03-05 22:06:19","user_id":"alica","board_name":"qna","action":"insert"}
Athena에서 테이블 생성 시 아테나가 사용되는 형식과 데이터 구문 분석 방법을 알 수 있도록 SerDe 라이브러리를 지정하면 된다.
CREATE EXTERNAL TABLE IF NOT EXISTS test.myjson (
`time` STRING,
`user_id` STRING,
`board_name` STRING,
`action` STRING
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' -- SerDe에 JSON 데이터 형식을 지정
LOCATION 's3://athena-log-test-11/jsonTest';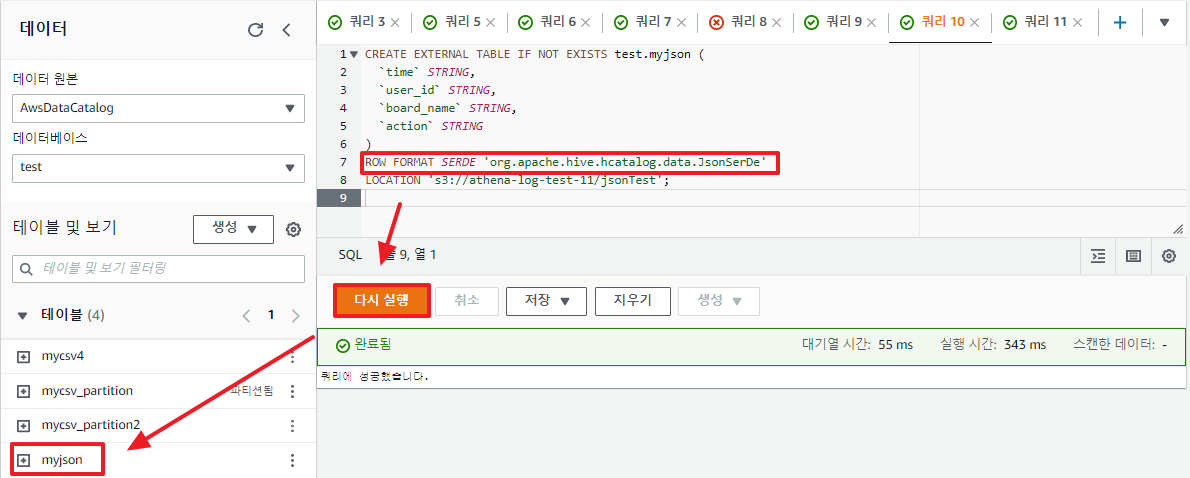
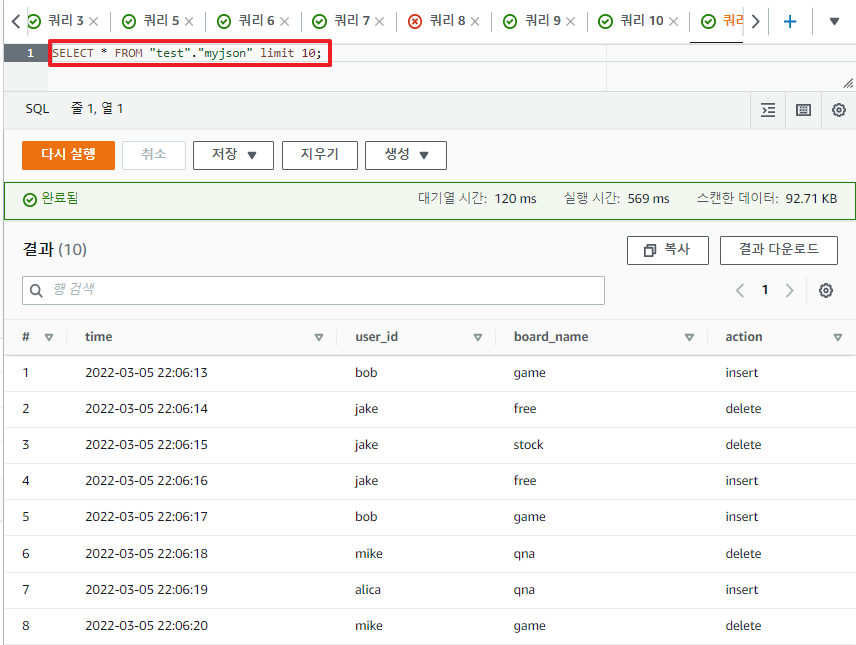
테이블을 조회해 보면 다음과 같이 json 데이터가 잘 테이블화 됨을 확인 할 수 있다.
만일 json 이외의 파일 형식을 사용한다면 다음 공식문서를 참고하길 바란다.
SerDe 참조 - Amazon Athena
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
AWS Glue를 이용한 자동 테이블 생성
AWS Glue 서비스는 AWS Glue는 완전 관리형 ETL(추출, 변환 및 로드) 서비스로, 간단하게 여러 데이터 스토어 및 스트림 간에 원하는 데이터를 분류, 정리, 보강, 이동한다.
EC2가 인스턴스(컴퓨팅)을 모아놓은 것이고, 람다가 함수들을 모아놓은 것이라면, Glue는 데이터들을 모아서 관리한다고 보면 된다.
이중에 Glue Crawler 기능을 통해 스키마 생성을 자동화 할 수 있다.
생소한 Athena create문 옵션을 달달 외우는 것보다 Glue Crawler를 이용하는 법을 고려해보는 것도 좋다.
[AWS] 📚 Glue Crawler로 테이블 만들고 Athena로 조회하기
Glue Crawler로 S3 스키마 생성 지난 포스팅에서는 csv파일을 S3에 업로드하고 Athena에서 직접 테이블 쿼리문을 실행하여 수동으로 만들어 조회하는 시간을 가져보았다. 이번에는 AWS Glue 서비스가 제
inpa.tistory.com
이 글이 좋으셨다면 구독 & 좋아요
여러분의 구독과 좋아요는
저자에게 큰 힘이 됩니다.


