...

Glue Crawler로 S3 스키마 생성
지난 포스팅에서는 csv파일을 S3에 업로드하고 Athena에서 직접 테이블 쿼리문을 실행하여 수동으로 만들어 조회하는 시간을 가져보았다.
이번에는 AWS Glue 서비스가 제공하는 Glue Crawler를 사용해 S3의 데이터를 스캔하고 자동으로 데이터베이스와 테이블을 만들어주는 서비스를 이용해 Athena로 조회해보는 시간을 가져볼 것이다.
Glue 크롤러로 파일을 데이터베이스로 변환하기 위해선 당연히 대상으로 하고 메타 테이블을 생성할 데이터 소스가 필요하다.
RDS, S3, DynamoDB 등 AWS의 데이터 저장소 뿐만 아니라 JDBC를 지원하는 DB, file 등등 거의 모든 형태의 데이터 저장소에 있는 파일을 이용해 크롤러가 가능하다.
이번 강의에서는 json 파일을 S3에 업로드하고 이를 데이터베이스화 해보자.
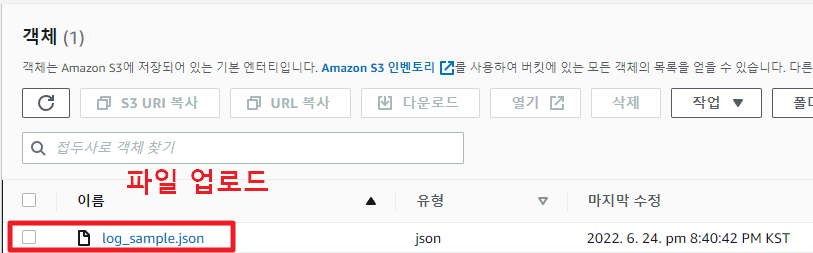
S3 버킷 생성 및 json 로그 올리기
{"time":"2022-03-05 22:06:13","user_id":"bob","board_name":"game","action":"insert"}
{"time":"2022-03-05 22:06:14","user_id":"jake","board_name":"free","action":"delete"}
{"time":"2022-03-05 22:06:15","user_id":"jake","board_name":"stock","action":"delete"}
{"time":"2022-03-05 22:06:16","user_id":"jake","board_name":"free","action":"insert"}
{"time":"2022-03-05 22:06:17","user_id":"bob","board_name":"game","action":"insert"}Glue 크롤러 생성하기
AWS Glue Crawler를 사용해 S3 버킷에 저장된 내용들을 쭉 살펴보고 스키마와 함께 테이블을 생성해준다.
그리고 이를 참고해서 Athena가 쿼리를 날릴수 있는 것이다.
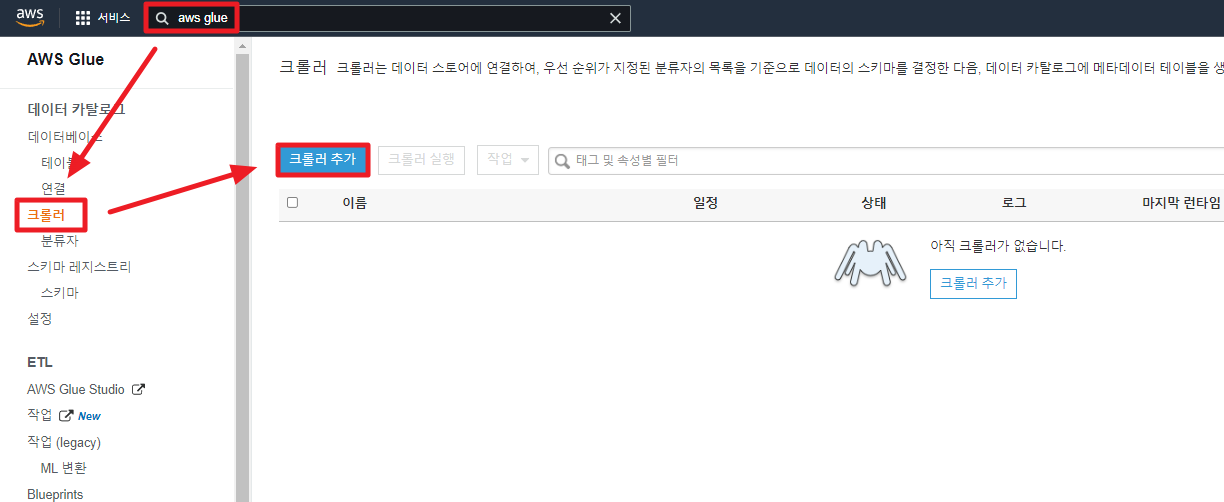
1. 크롤러 정보 설정
간단하게는 이름만 설정하고 넘어가도 된다.
밑의 태그, 설명, 보안구성, 분류자 옵션 설정에서 특별한건 없지만, 분류자는 때에 따라서 필요할 수 있다.
csv 파일일 때 특히 그런데, 일반적으로 쉼표를 구분자로 사용하긴 하지만 구분자가 통일되지 않은 경우 분류자를 이용해 구분자를 통일할 수 있다.
2. 크롤러 소스 타입
Data store(데이터 저장소)를 바라볼지, 기존에 생성한 Data Catalog의 메타 데이터 테이블을 바라볼 지 선택한다.
3. 데이터 스토어 추가
메타 테이블을 생성할 데이터 저장소를 1개 혹은 여러 개 추가할 수 있다.
위에서 만든 버킷경로를 포함 경로 란에 추가해준다.
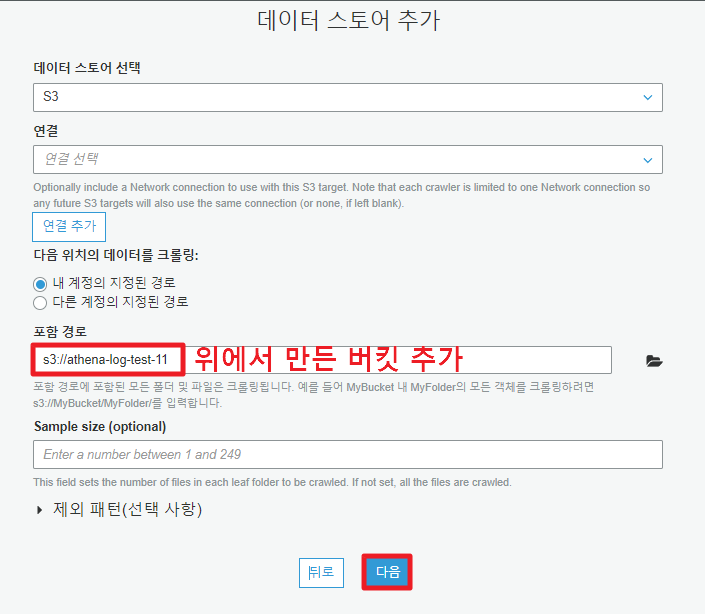
더 추가할 지 물어보는 옵션이 나오면 아니오를 선택하고 다음을 눌러준다.

4. IAM 규칙 설정
본래 AWS에서는 S3에 액세스 하기 위해서는 IAM 권한이 필요했다.
Glue Crawler도 예외가 아니며, 이 단계에서 IAM 역할을 생성해서 등록해줄 수 있다.
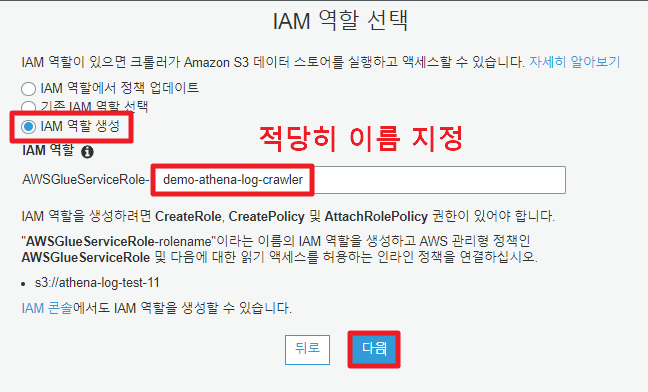
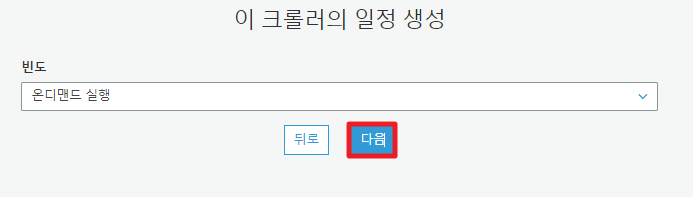
5. 스케쥴 설정
크롤러의 작동 스케줄을 설정할 수 있다.
시간마다, 일마다, 주마다 등 기본 옵션이 있고 직접 커스텀하거나 원할때만 작동하도록 고를 수도 있다.
보통 온디멘드(Run on demand)를 설정한 뒤 필요한 경우에만 람다(서버리스) 등으로 실행 시키는 식으로 사용하면 된다.
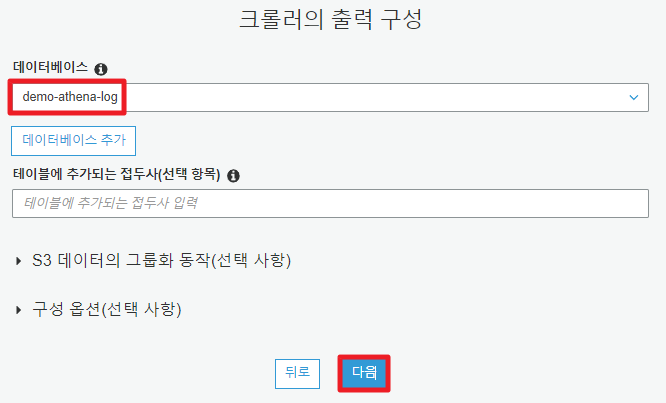
6. 크롤러 출력 결과 저장소 설정
메타 테이블(Cralwer 결과)을 저장할 곳을 지정한다.
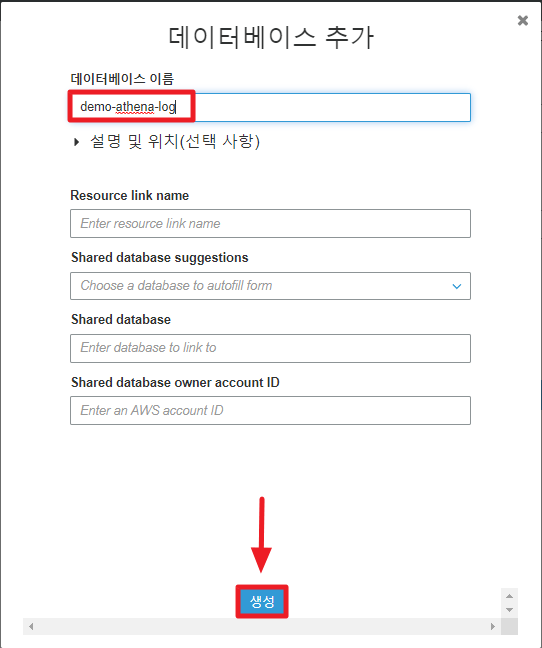
Add database로 바로 만들어 보자.
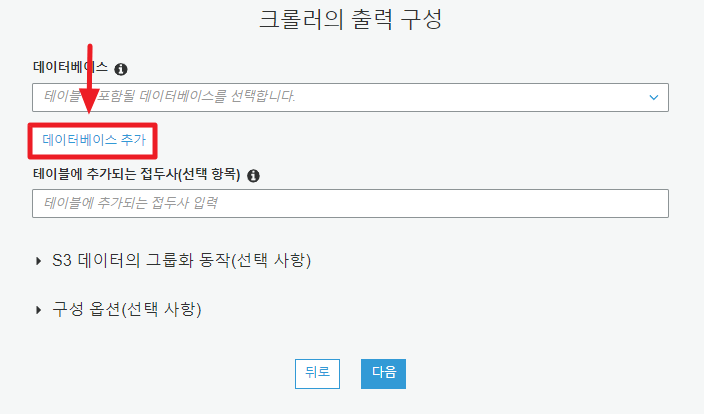
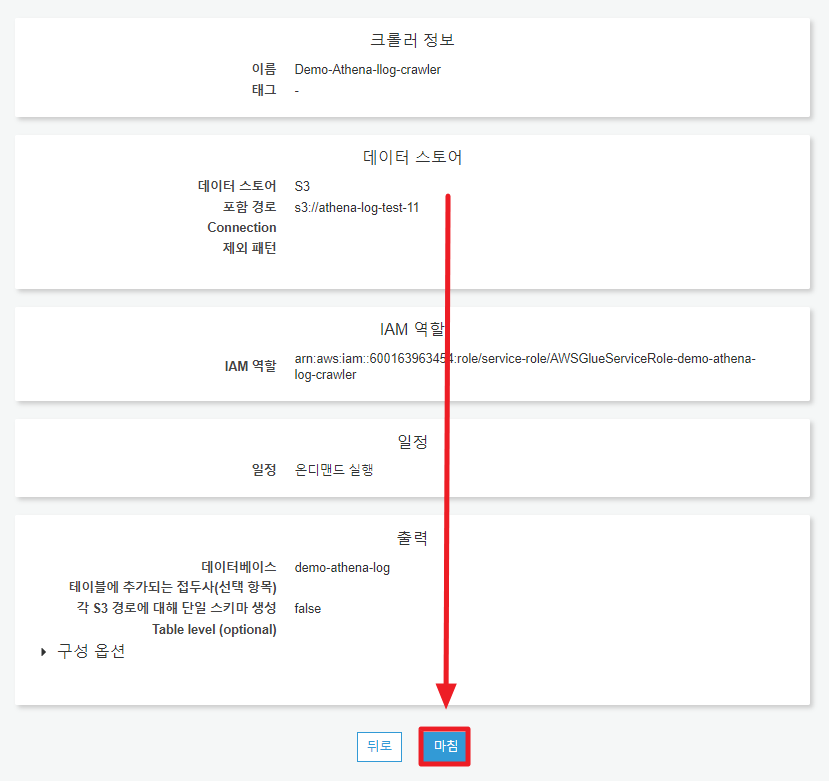
8. 최종 확인
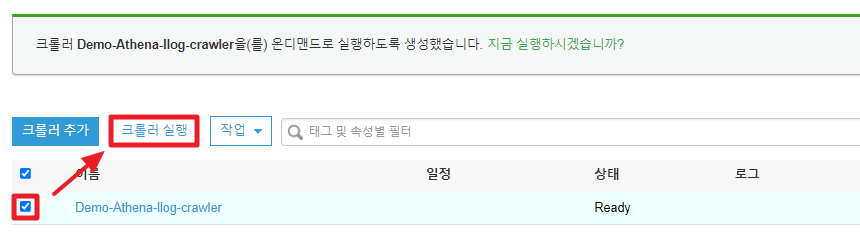
10. 크롤러 실행
이제 등록한 크롤러를 실행해서 S3에 있는 데이터를 테이블화 한다.
파일의 데이터가 클수록 1분 이상 걸릴수 있으니 천천히 기다리자.
kb 단위의 작은 파일로 실습을 하고 있어 크게 상관없지만, glue는 서비스 요금이 꽤 비싼 편에 속하기 때문에 혹시 모를 요금폭탄에 주의하자.
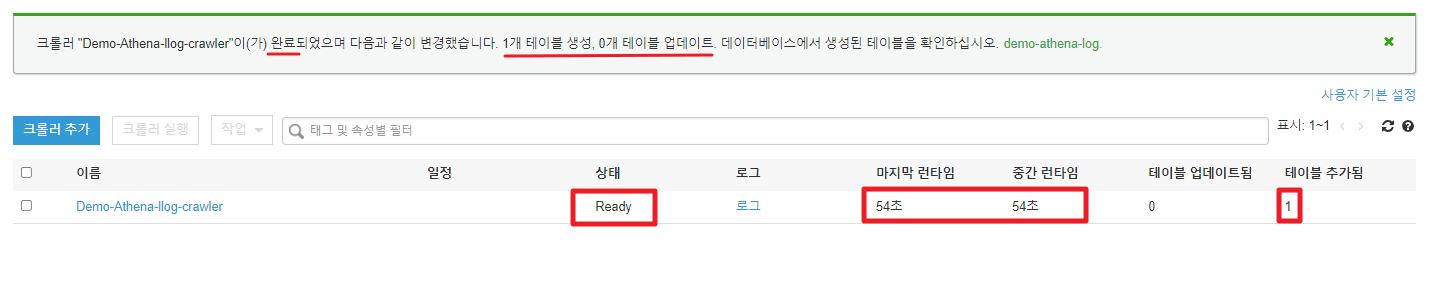
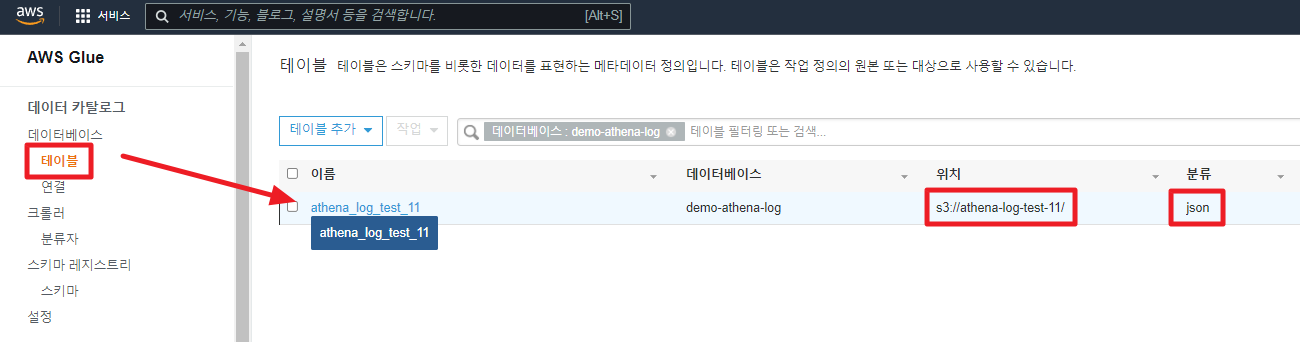
11. 테이블 확인하기
생성이 완료되면 데이터베이스 테이블 메뉴에서 생성한 스키마를 확인 할 수 있다.
Athena에서 직접 쿼리문으로 만든 테이블도 AWS Glue 테이블 카탈로그에 저장되게 된다.
한마디로 Athena의 테이블은 여기에서 관리된다라고 보면 된다.
Athena로 테이블 조회하기
Glue 크롤러로 만든 데이터베이스 테이블을 Athena 서비스로 조회해보자.
그 이전에, 먼저 쿼리 결과를 저장할 위치를 설정해주어야 한다. 우측에 보기 설정을 눌러 S3 경로를 설정해 주자.
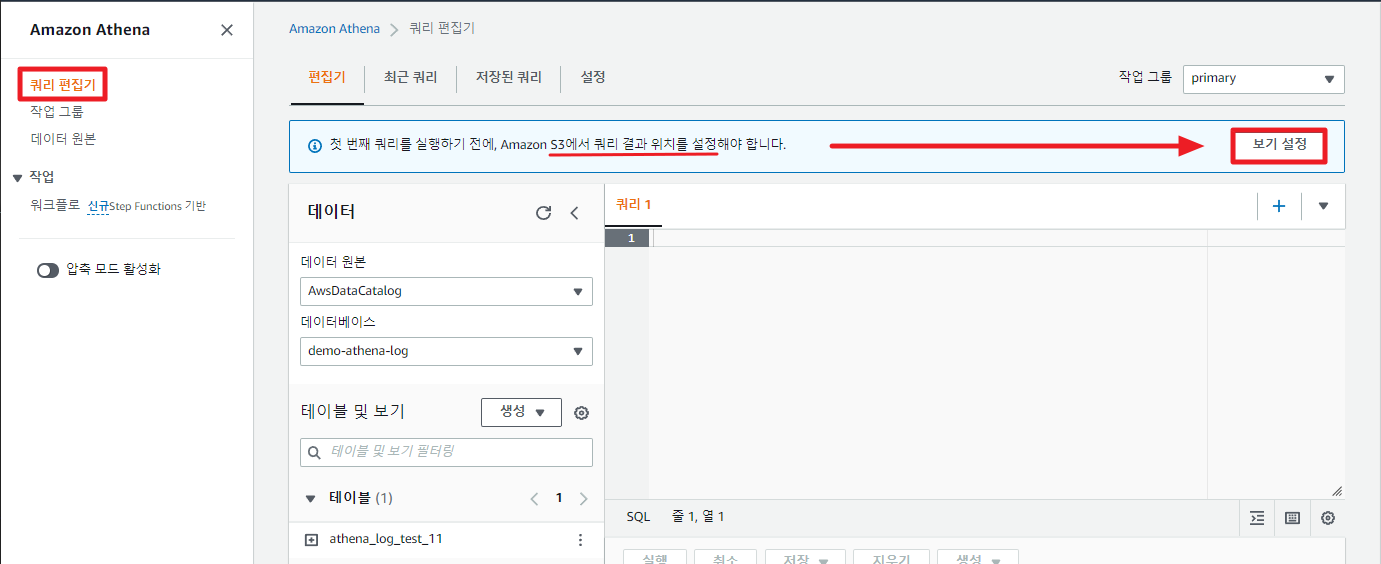
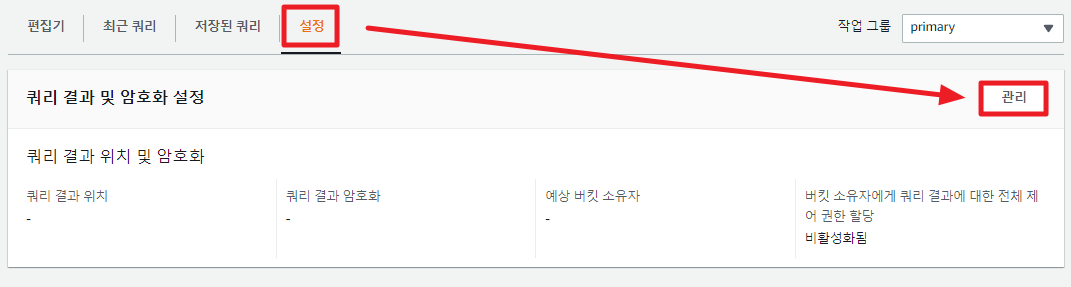
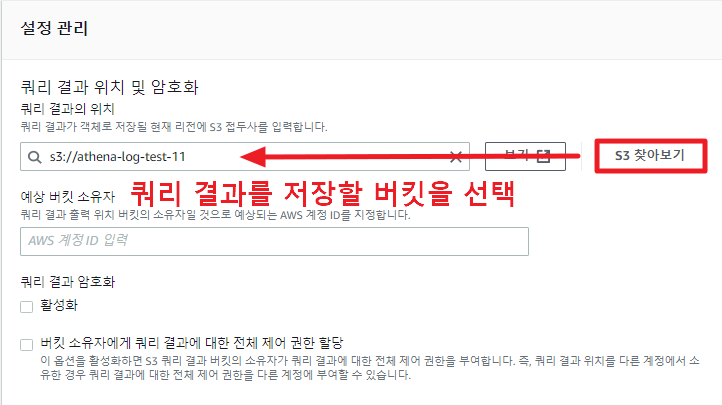
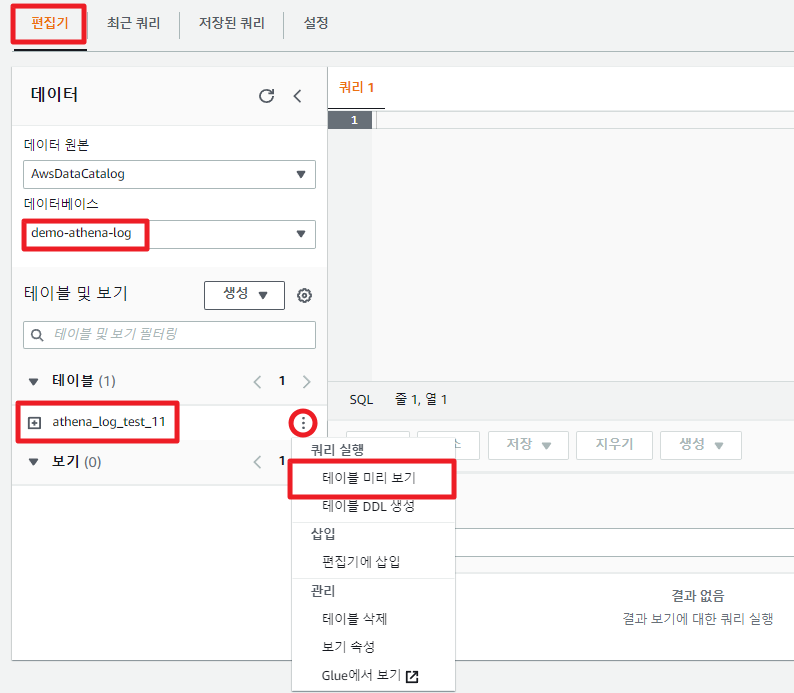
이제 Glue 크롤러에서 생성한 데이터베이스를 선택해주면, 하단에 테이블명이 나타나게 된다.
테이블 내용을 조회해 보자.
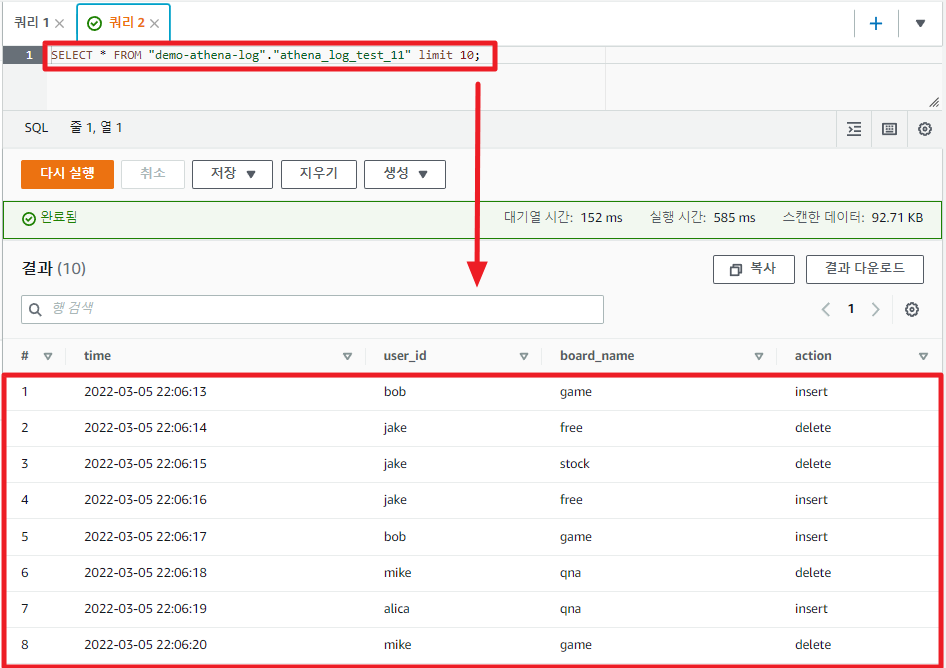
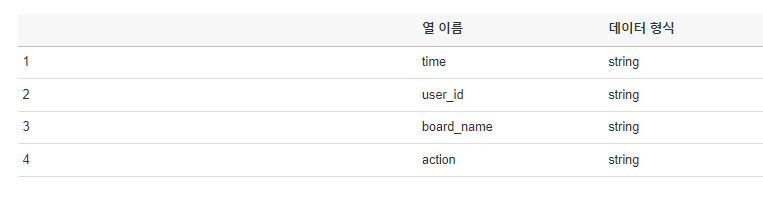
json의 데이터가 테이블 형식으로 잘 변환되어 조회됨을 확인 할 수 있다.
이번에는 쿼리의 내용을 바꾸어 질의 해보자.
SELECT * FROM "demo-athena-log"."athena_log_test_11" where user_id = 'bob'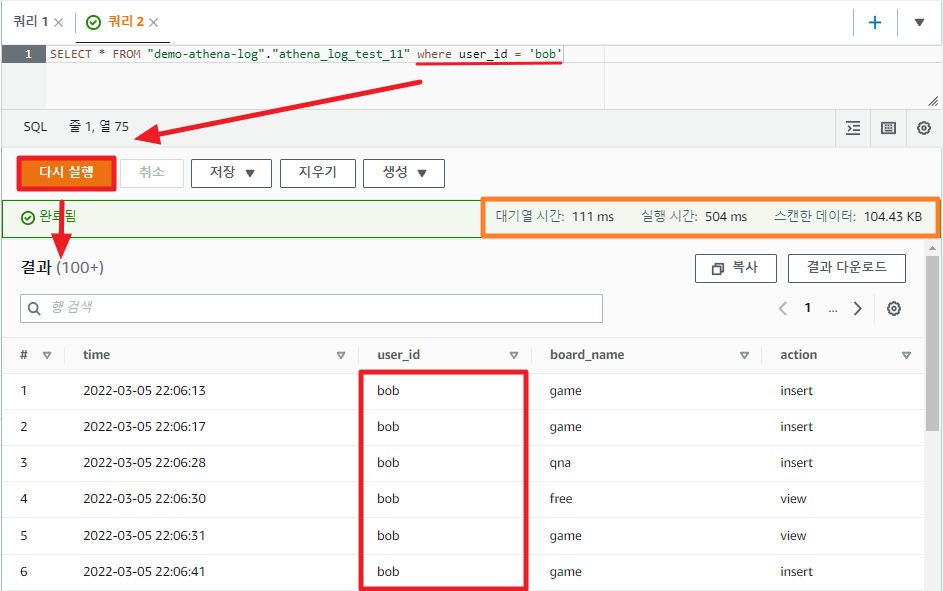
다음과 같이 time 필드를 순서대로 정렬시켜 질의 하면 시간마다 로그의 상태를 볼수 있다.
SELECT * FROM "demo-athena-log"."athena_log_test_11"
where user_id = 'bob'
order by time desc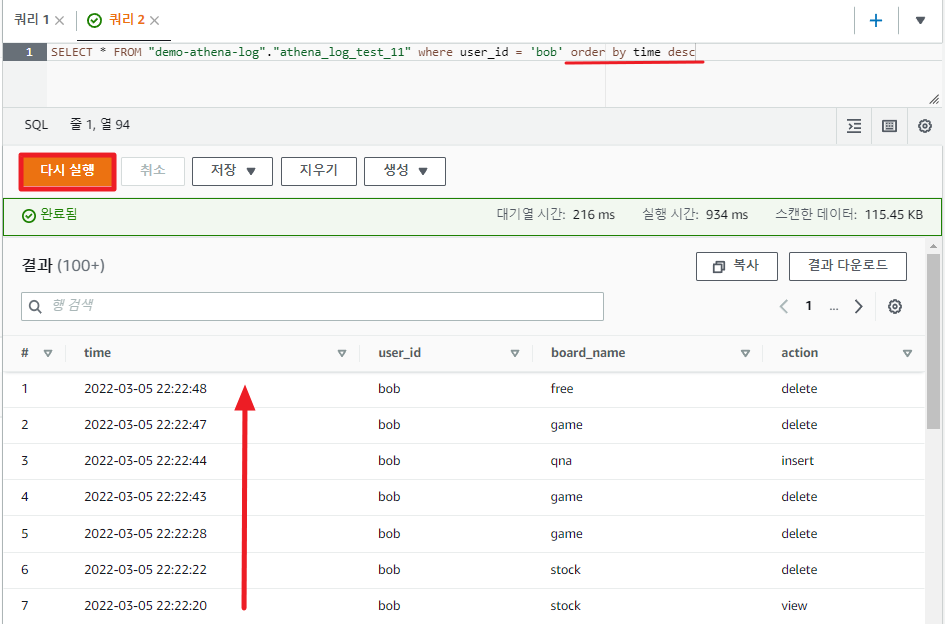
이번엔 action 필드가 'insert'인 쿼리를 조회해서 집계함수로 조회해보자.
SELECT count(*)
FROM "demo-athena-log"."athena_log_test_11"
where user_id = 'bob' and action = 'insert'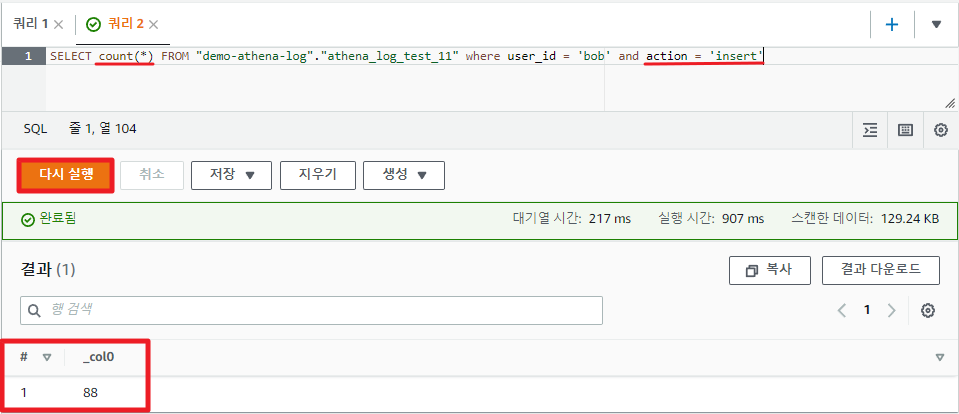
이 글이 좋으셨다면 구독 & 좋아요
여러분의 구독과 좋아요는
저자에게 큰 힘이 됩니다.


