...

HTTP / 0.9

HTTP의 시작은 1989년 팀 버너 리(Tim Berners-LEE)에 의해 제안된 인터넷의 하이퍼 텍스트 시스템이다.
초기 버전인 HTTP/0.9는 매우 단순한 프로토콜이었다.
가능한 메서드는 하이퍼텍스트 문서(html)를 가져오기만 하는 GET 동작이 유일했으며, 헤더(header)도 없어 요청과 응답이 극히 단순 명료 하였다. 또한 상태 코드(status code)도 없었기 때문에 문제가 발생한 경우 특정 html 파일을 오류에 대한 설명과 함께 보내졌다.
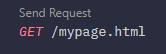
<HTML>
A very simple HTML page
</HTML>HTTP 0.9 스펙을 요약하면 다음과 같다.
- TCP/IP 링크 위에서 동작하는 ASCII 프로토콜
- Get 메서드만 지원
- HTTP 헤더 X, 상태 코드 X
- 응답도 HTML 파일 자체만 보내줌
- 서버와 클라이언트 간의 연결은 모든 요청 후에 닫힘(closed)
사실 초기에는 버전 번호가 존재하지 않았지만, 이후에 다른 http 버전들과 구분하기 위해서 0.9라는 버전을 붙이게 되었다고 한다.
HTTP는 이러한 비교적 단순한 형태로 1991년에 시작되어, 이후 빠르게 진화하고 발전하게 되어지기 시작 했다.
HTTP / 1.0
인터넷의 성장이 날이 갈수록 거대해지면서, 1994년 W3C가 만들어지며 HTML의 발전을 도모하게 되었고, 이와 비슷하게 HTTP 프로토콜 개선에 초점을 맞추기 위해 HTTP-WG(HTTP Working Group)가 설립되었다.
웹 브라우저, 인터넷 인프라가 빠르게 진화하며 이제는 단순히 하이퍼텍스트 문서 뿐만 아니라 멀티미디어 데이터나 메타데이터 등 다양하고 상세한 컨텐츠가 필요해짐으로써, 기존의 HTTP 0.9로는 다양한 요구사항들을 채울수 없는 한계에 봉착하게 되었다.
그러다 1996년 HTTP-WG는 HTTP/1.0 구현의 일반적인 사용을 문서화한 RFC 1945를 발표하게 된다.
RFC 1945는 어렵게 생각할 필요없이 HTTP 1.0 프로토콜 통신 스펙에 관한 기술 문서 정도로 생각하면 된다.
컨텐츠 인코딩, 다양한 글자 지원, 멀티파트 타입, 인가, 캐싱, 프록시, 날짜 형식 등을 문서화 하였다.
이는 다음과 같은 익숙한 형태의 요청과 응답 포맷으로 구성되었다.
Request 메세지에는 GET 요청이 시작되는 줄에 PATH와 HTTP 버젼 그리고 다음 줄로 이어지는 헤더값을 가지며, Response 메세지에는 200 OK 이후 응답 상태로 이어지는 응답 헤더값을 가지는 걸 볼 수 있다.
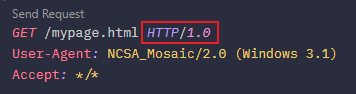
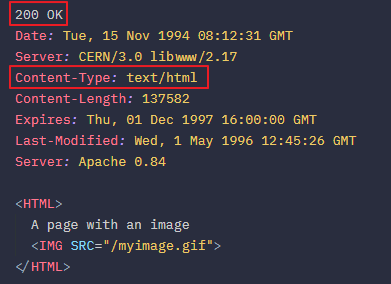
이른바 HTTP 포맷 형태의 시초라고 보면 된다.
이렇게 발표된 HTTP 1.0 스펙을 요약하면 다음과 같다.
- 기본적인 HTTP 메서드와 요청/응답 헤더 추가
- HTTP 버전 정보가 각 요청 사이내로 전송되기 시작 (HTTP/1.0 이 GET 라인에 붙은 형태로)
- 상태 코드(status code)가 응답의 시작 부분에 붙어 전송되어, 브라우저가 요청에 대한 성공과 실패를 알 수 있고 그 결과에 대한 동작을 할 수 있게 되었다. (특정 방법으로 로컬 캐시를 갱신하거나 ..등)
- 응답 헤더의 Content-Type 덕분에 HTML 파일 형식 외에 다른 문서들을 전송하는 기능이 추가되었다.
- 단기커넥션 : connection 하나당 1 Request & 1 Response 처리 가능
HTTP 1.0 문제점
Short-lived Connection
HTTP 1.0의 문제점은 비연결성(connectionless)로 인한 단기 커넥션(Short-lived connenction) 특징이다.
즉, 커넥션 하나당 하나의 요청 하나의 응답 처리가 가능한 것을 말하는데, 서버에 자원을 요청할때마다 매번 새로운 연결을 해주어야 했다.
- 1 Request & 1 response
- 매번 새로운 연결로 성능 저하
- 매번 새로운 연결로 서버 부하 비용 증가
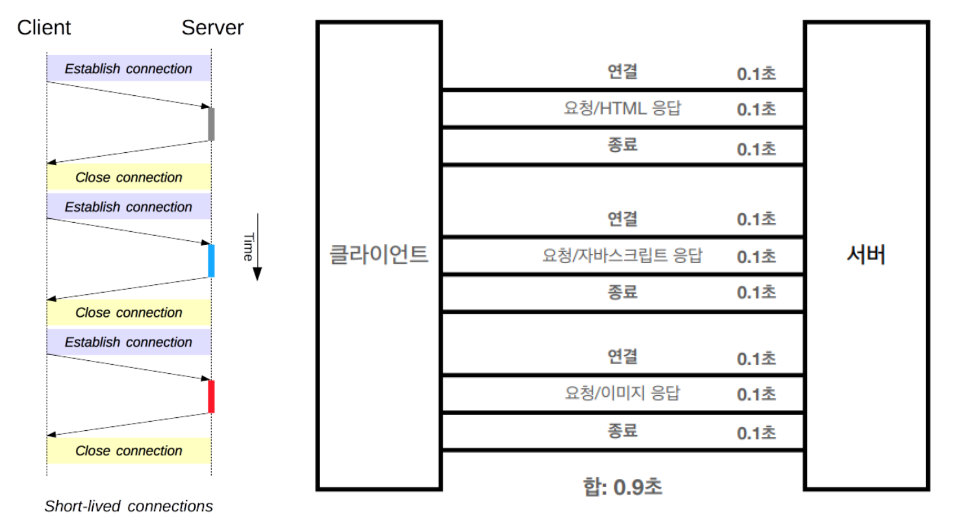
예를들어 웹페이지를 요청하면 html과 그에 딸린 css나 js 및 이미지 등등 수 많은 자원들이 다운로드되어 화면에 띄울 텐데, 각 자원들을 따로 따로 매번 TCP 연결하고 다운받고 연결 끊고 다시 연결하고 다운 받고 연결 끊는 것이다.
그래서 HTTP 초기에는 모든 자료에 대해서 비연결성으로 각각의 자원에 대해 연결/응답/종료를 반복하다보니 느렸다.
HTTP / 1.1
HTTP 1.0의 몇가지 단점을 커버하기 위해 HTTP 1.0이 출시된지 6개월 만에 1997년 1월에 공식적으로 HTTP/1.1이 릴리즈 되게 된다.
HTTP 1.1은 현재 가장 많이 쓰이는 프로토콜 버젼이며, 우리가 HTTP를 학습할때 배우는 기본 베이스 지식이기도 하다.
HTTP 1.1 표준은 이전 버전에서 발견 된 많은 프로토콜 모호성을 해결하고 몇 가지 크리티컬한 성능 개선을 도입했다.
좀더 보완된 특징은 다음과 같다.
- 지속 연결(Persistent connection) : 지정한 timeout 동안 연속적인 요청 사이에 커넥션을 닫지 않음. 기존 연결에 대해서 handshake 생략 가능
- 파이프 라이닝(pipelining) : 이전 요청에 대한 응답이 완전히 전송되기 전에 다음 전송을 가능하게 하여, 여러 요청을 연속적으로 보내 그 순서에 맞춰 응답을 받는 방식으로 지연 시간을 줄이는 방식 (불안정하여 사장됨)
- HOST 헤더 추가 : 동일 IP 주소에 다른 도메인을 호스트하는 기능 가능
- Chunk Encoding 전송 : 응답 조각
- 바이트 범위 요청
- 캐시 제어 메커니즘 도입
Persistent Connection (keep-alive)
HTTP는 TCP 연결 기반 위에서 동작하는 프로토콜로 신뢰성 확보를 위해 연결을 맺고 끊는 데 있어서 3 way Handshake 가 이루어진다. 그런데 HTTP는 기본적으로 비연결성(connecitonless) 프로토콜이기 때문에 한 번의 요청과 응답을 하고 응답이 끝나면 연결을 끊어 버리는데, 자원을 요청할때 마다 연결을 맺고 끊어버려 오버헤드(overhead)가 생기게 된다.
그래서 HTTP/1.1에서 Persistent Connection 기능이 추가됨으로써, 한 번 맺어졌던 연결을 끊지 않고 지속적으로 유지하여 불필요한 Handshake를 줄여 성능을 개선하였다.
- 연결을 유지함으로써 Handshake 과정을 생략해 빠르게 자원을 받아올 수 있다.
- 불필요한 연결의 맺고 끊음을 최소화시켜 네트워크 부하를 줄 일 수 있다.
- 클라이언트 측에서 요청에 keep-alive 헤더를 담아 보내야 한다.
- 정확한 Content-length 헤더를 사용해야 한다. 하나의 connection을 계속해서 재사용해야 하는데, 특정 요청의 종료를 판단할 수 없기 때문이다.
- Connection 헤더를 지원하지 않는 proxy에는 사용할 수 없다.
가끔 HTTP 지속 연결을 persistent connection 혹은 keep-alive connection 으로 용어를 혼재하는데, 정확히는 persistent connection이 맞다.
keep-alive는 HTTP 1.0+이 persistent connection을 연결하기 위해, 헤더에 명시해 사용하는 단어라고 보면 된다.
keep-alive 동작 과정
Keep-Alive는 원리는 단순하다.
지정한 timeout동안 연결을 끊지 않게 지정해서, HTTP 요청과 응답 시 다수의 TCP 연결 handshake를 줄이는 것에 초점을 둔다.
HTTP/1.1부터는 keep-alive가 기본으로 세팅되어 자동으로 Persistent Connection 연결이 된다. 하지만 기본적으로 HTTP/1.0 connection은 하나의 request에 응답할 때마다 connection을 close하도록 설정돼있다.
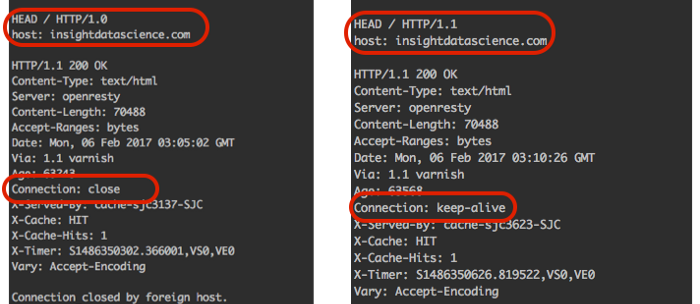
따라서 HTTP/1.0+ 기반에서 TCP 연결의 재사용을 원할때 아래처럼 요청 헤더 Connection 속성에 keep-alive를 세팅해야 한다는 특징이 있다.
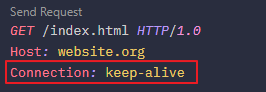
만약 서버에서 keep-alive connection을 지원하는 경우에는 동일한 헤더를 response에 담아 보내주고, 지원하지 않으면 헤더에 담아 보내주지 않는다. 만약 서버의 응답에 해당 헤더가 없을 경우 client는 지원하지 않는다고 가정하고 connection을 재사용하지 않게 된다.
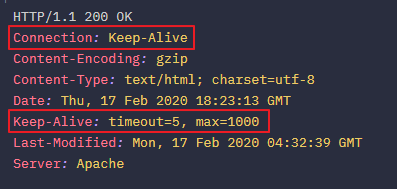
- max : keep-alive을 통해서 주고받을 수 있는 request의 최대 갯수. 이 수보다 더 많은 요청을 주고 받을 경우에는 connection은 close된다.
- timeout : keep-alive가 얼마동안 유지될 것인가를 의미한다. 이 시간이 지날 동안 request가 없을 경우에 connection은 close된다
keep-alive를 이용한 통신은 위의 설정에 따라 클라이언트나 서버 중 한쪽이 다음 헤더를 부여해 접속을 끊거나 타임아웃될 때까지 연결이 유지된다. 그래서 만일 필요한 자원을 모두 할당받고 더이상 keep-alive 연결을 유지할 필요가 없을 경우 요청 헤더에서 Connection 속성을 close로 설정해 서버로 보내게 되면, TCP 지속 연결을 끊게 된다.
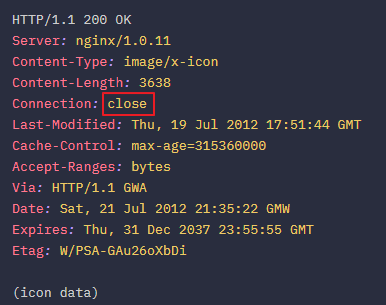
keep-alive 메세지 통신
다음은 두개의 요청에 대한 HTTP 메세지 예시이다.
먼저 HTML 페이지에 대한 요청을 하고 그다음 아이콘 이미지에 대한 요청을 한다. 이 2가지 요청은 모두 한 개의 keep-alive 연결을 통해 전달된다.
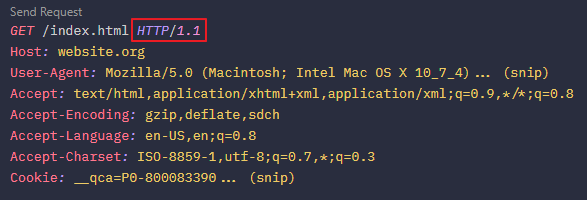
1. HTML 파일 요청 (인코딩, charset과 쿠키 메타데이터와 함께)
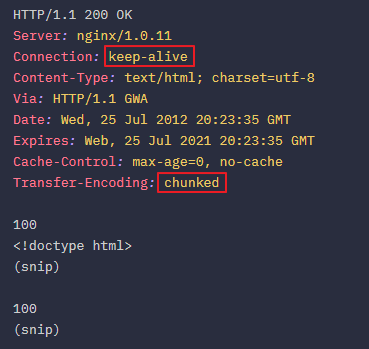
2. HTML 요청에 대한 응답
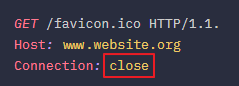
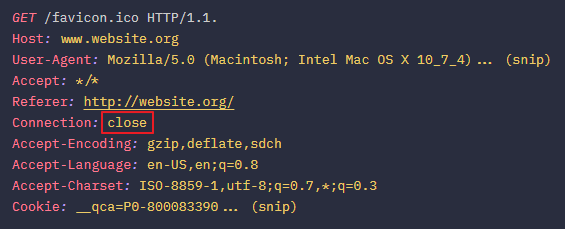
3. 동일한 TCP 연결에 발생한 icon 파일 요청 (icon 파일을 받고나면 서버에게 해당 연결이 재사용되지 않을 것임을 알리기 위에 Connection 헤더값을 close로 설정)
4. icon 응답과 연결 종료
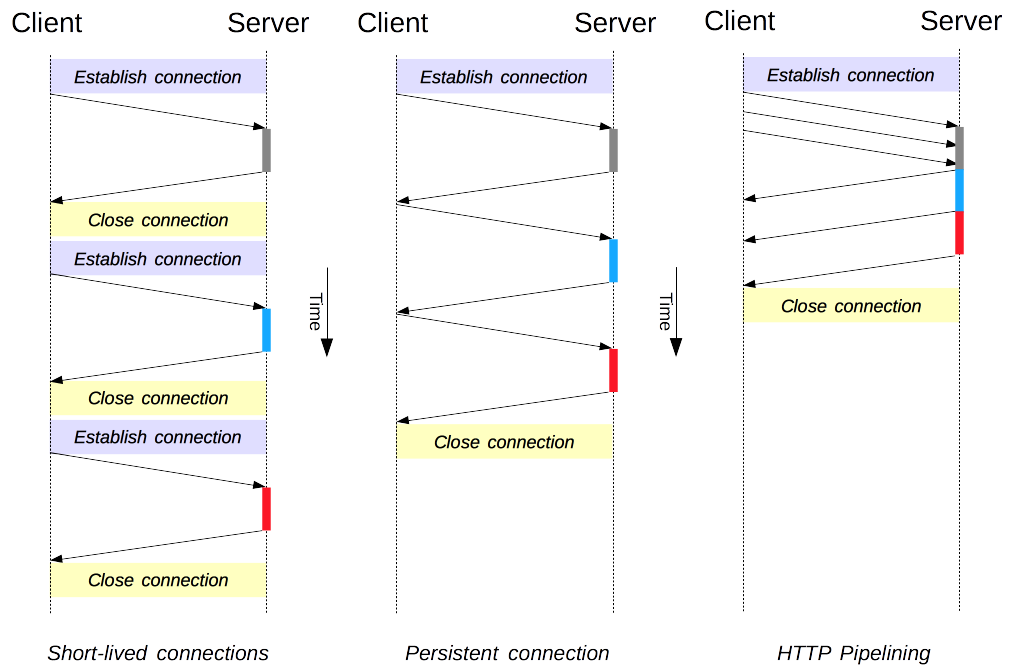
Pipelining
파이프 라이닝은 여러개의 요청을 보낼때 처음 요청이 응답될 때까지 기다리지 않고 바로 요청을 한꺼번에 보내는 것을 의미한다. 즉, 여러개의 요청을 한꺼번에 보내서 응답을 받음으로서 대기시간을 줄이는 기술이다.
- keep-alive를 전제로 하며, 서버 간 요청의 응답속도를 개선시키기 위해 적용
- 서버는 요청이 들어온 순서대로(FIFO) 응답을 반환한다.
- 하지만 응답 순서를 지키기 위해 응답 처리를 미루기 때문에 Head Of Line Blocking 문제가 발생하여, 그래서 모던 브라우저들은 대부분 파이프라이닝을 사용하지 못하도록 막아 놓았다.
- HTTP 2에서는 멀티플렉싱 알고리즘으로 대체되었다.
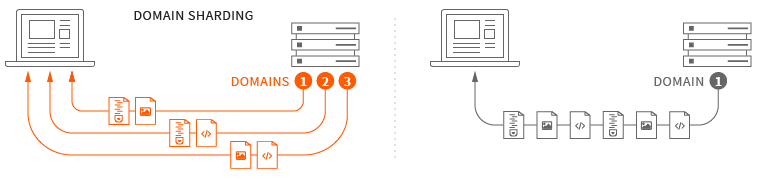
Domain Sharding
파이프라이닝을 대체하기 위한 차선책으로 나온 기술이며, 브라우저들은 하나의 도메인에 대해 여러 개의 Connection을 생성해서 병렬로 요청을 보내고 받는 방식으로 성능을 개선했다.
한 도메인당 6~13개의 TCP 연결들을 동시 생성해 여러 리소스를 한 번에 다운로드 하는 것이다. 이를 Domain Sharding이라고 부른다.
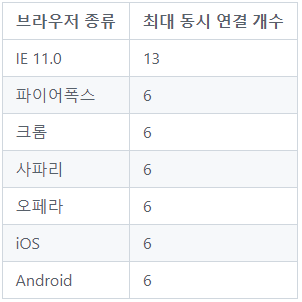
하지만 도메인의 주소를 찾기 위해 DNS Lookup 과정에서 시간을 잡아먹을수도 있으며, 브라우저별로 Domain당 Connection 개수의 제한이 존재하여 근본적인 해결책은 아니었다.
HTTP/1.1 문제점
HOLB (Head Of Line Blocking)
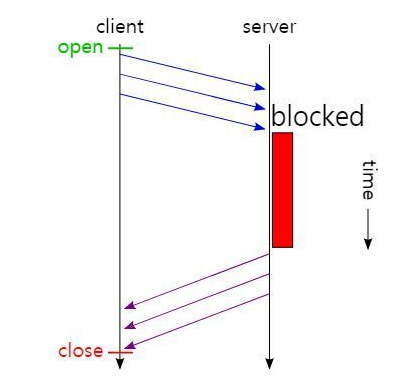
위에서 소개한 파이프 라이닝은 어찌보면 정말 혁신적인 기술이지만, 보낸 요청 순서대로 응답을 받아야하는 규칙 부분에서 문제가 생기게 된다.
마치 FIFO(선입선출) 처럼 생각하면 되는데, 문제는 요청하는 데이터의 크기는 제각각 이기 때문에, 첫번째로 요청한 데이터가 용량이 큰 데이터라면, 두번째, 세번째 데이터가 아무리 빨리 처리되어도 우선순위 원칙에 따라 첫번째 데이터의 응답 속도가 늦어지면 후 순위에 있는 데이터 응답속도도 덩달아 늦어지게 되는 것이다.
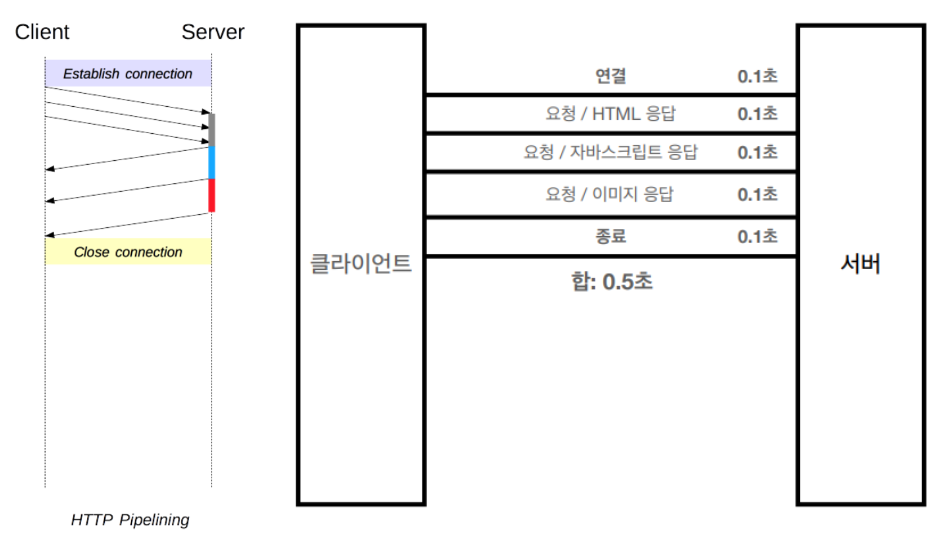
이해가 잘 되지 않는다면 아래 그림을 살펴보자.
첫번째 http request에서는 하나의 요청당 응답을 받아야 다음 요청을 보내는 오래된 방법으로 time 길이를 보면 오래 걸려 길다. 그래서 pipelining을 통해 동시 요청을 통해 time을 감소 시켰지만, 문제는 첫번째 요청에 대한 응답이 오래걸릴 경우 그 뒤의 응답도 같이 늦게 되서 결과적으로 총 time이 길어지게 되는 비효율적인 상황이 발생하게 되는 것이다.
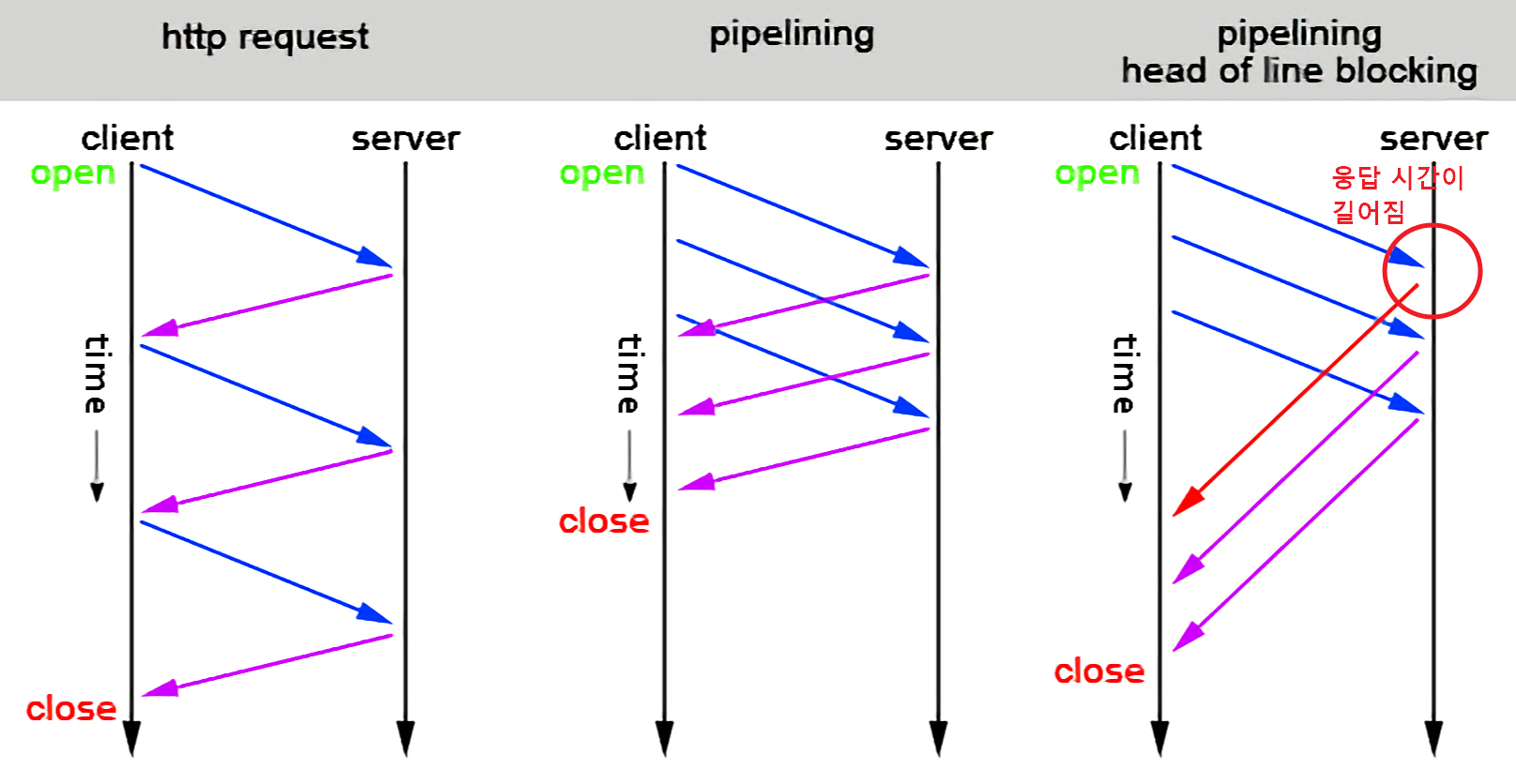
따라서 위의 문제점과 더불어 구현 복잡성에 의해 파이프 라이닝은 활용이 매우 제한적이었으며, 대부분의 브라우저에서는 여러개의 tcp 연결을 만들어 병렬적으로 이용하는 방식을 많이 사용하였지만 이 역시 추가 메모리와 리소스를 낭비하는 단점이 있었다.
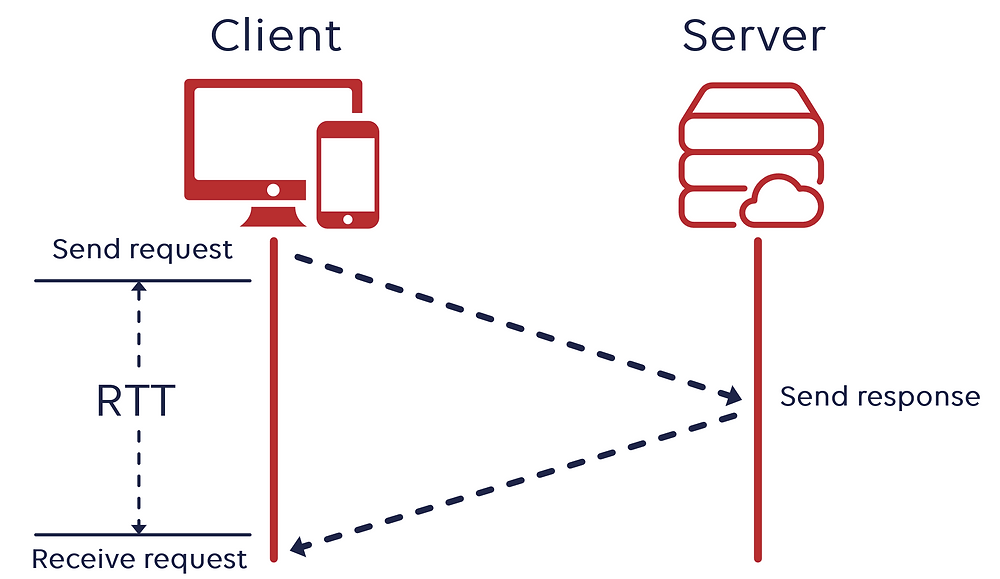
RTT (Round Trip Time)
RTT(Round Trip Time)란, 요청(SYN)을 보낼 때부터 요청에 대한 응답(SYN+ACK)을 받을 때까지의 왕복 시간을 의미한다.
즉, 아무리 keep-alive 라고 하지만 결국 TCP상에서 동작하는 HTTP의 특성상 Handshake 가 반복적으로 일어나게 되어 불필요한 RTT증가로 인해 네트워크 지연을 초래하여 성능이 저하되게 된다.
예전에는 컨텐츠가 지금처럼 많지 않았기에 큰 부담은 아니었지만, 점점 컨텐츠가 증가하면서 이러한 레이턴시도 부담스러워 졌다.
무거운 헤더 구조와 중복
http/1.1의 헤더에는 많은 메타정보들이 저장되어져 있다. 또한 해당 도메인에 설정된 cookie정보도 매 요청시 마다 헤더에 포함되어 전송되기 때문에 오히려 전송하려는 값보다 헤더 값이 더 큰 경우가 비일비재 하였다.
그리고 지속 커넥션 속에서 주고 받는 연속된 요청 데이터가 중복된 헤더값를 가지고 있는 경우가 많아 쓸데없는 메모리 자원도 낭비하게 되는 꼴이 되었다.

HTTP 1.1을 개선한 HTTP 2.0
HTTP 2.0은 기존 HTTP 1.1 버전의 성능 향상에 초점을 맞춘 프로토콜이다.
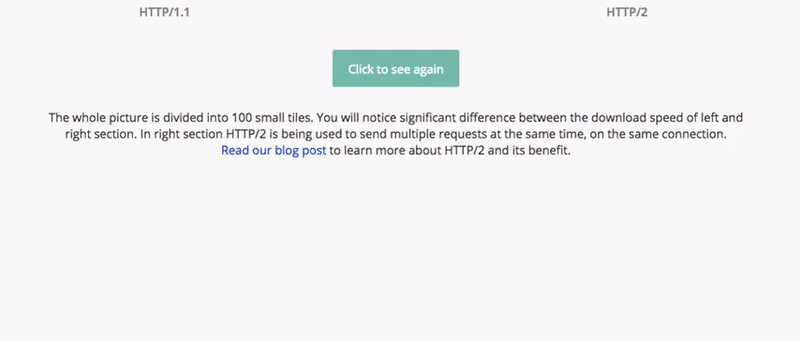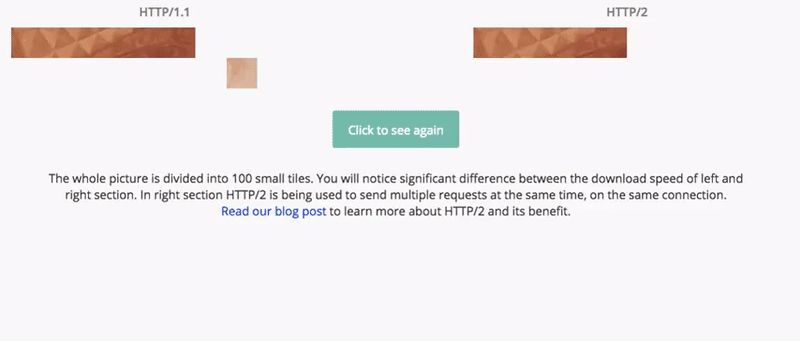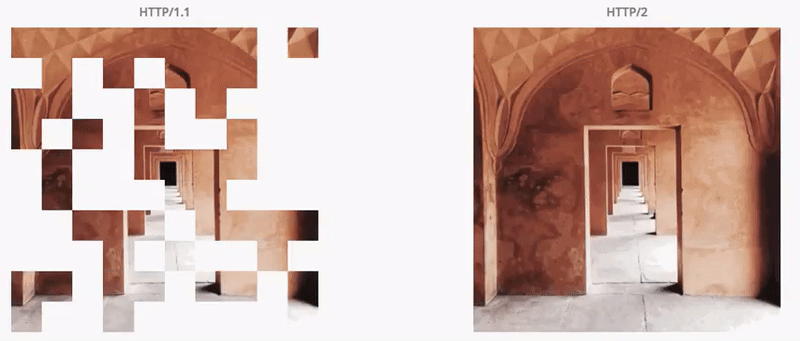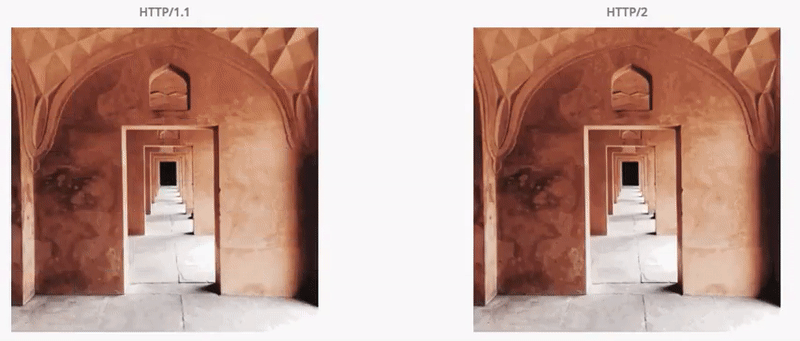
기존의 HTTP 1.1의 내부적인 통신 구조를 다른 개념으로 송두리째 바꿔버렸는데, 웹 응답 속도가 HTTP/1/1에 비해 15~50% 향상 되었다.
아래 그림을 보면 고용량 이미지에 대해서 응답속도 비교를 한눈에 볼 수 있다.
[WEB] 🌐 HTTP 2.0 통신 기술 - 자신있게 이해하기
HTTP / 2.0 HTTP 2.0은 기존 HTTP 1.1 버전의 성능 향상에 초점을 맞춘 프로토콜이다. 인터넷 프로토콜 표준의 대체가 아닌 확장으로써, HTTP 1.1의 성능 저하 부분과 비효율적인 것들을 개선되어 탄생한
inpa.tistory.com
# 참고자료
HTTP 완벽 가이드 - Programming Insight
https://kyun2da.dev/cs/http%EC%9D%98-%EC%97%AD%EC%82%AC%EC%99%80-http2%EC%9D%98-%EB%93%B1%EC%9E%A5/
https://www.imperva.com/learn/performance/http-keep-alive/
이 글이 좋으셨다면 구독 & 좋아요
여러분의 구독과 좋아요는
저자에게 큰 힘이 됩니다.


