일반적으로 캐시(cache)는 메모리(RAM)를 사용하기 때문에 데이터베이스 보다 훨씬 빠르게 데이터를 응답할 수 있어 이용자에게 빠르게 서비스를 제공할 수 있다.
하지만 기본적으로 RAM의 용량은 커봐야 16 ~ 32G 정도라, 데이터를 모두 캐시에 저장해버리면 용량 부족 현상이 일어나 시스템이 다운 될 수 있다.
따라서 어느 종류의 데이터를 캐시에 저장할지, 얼만큼 데이터를 캐시에 저장할지, 얼마동안 오래된 데이터를 캐시에서 제거하는지에 대한 '지침 전략' 을 숙지할 필요가 있다.
캐시를 효율적으로 이용하기위해서는 캐시에 저장할 데이터 특성도 고려해야 한다. 예를들어 자주 조회되는 데이터, 결과값이 자주 변동되지 않고 일정한 데이터, 조회하는데 연산이 필요한 데이터를 캐싱해두면 좋다.
이전 Redis를 소개하는 글 에서 잠깐 레디스 캐시 활용사례를 들었었는데, 이번 시간에는 캐시 배치 전략 종류에 대해 좀더 상세히 알아보고, redis에서 캐쉬를 다룰때 어떤 점을 유의해서 설계 해야 되는지적절한 캐싱 전략 선택 지침 이론을 정리해 볼 예정이다.
노드나 스프링으로 서버를 만드는데 있어, 자신의 프로젝트에 캐시 메모리를 적용하려 할때, 요청(request)이 라우터에 오면 어느 상황에서 어떤식으로 캐시를 사용할 것인지 보다 효율적으로 서비스가 빠릿빠릿하게 돌아가도록 설계 하는데 있어 참고가 되기를 바란다.
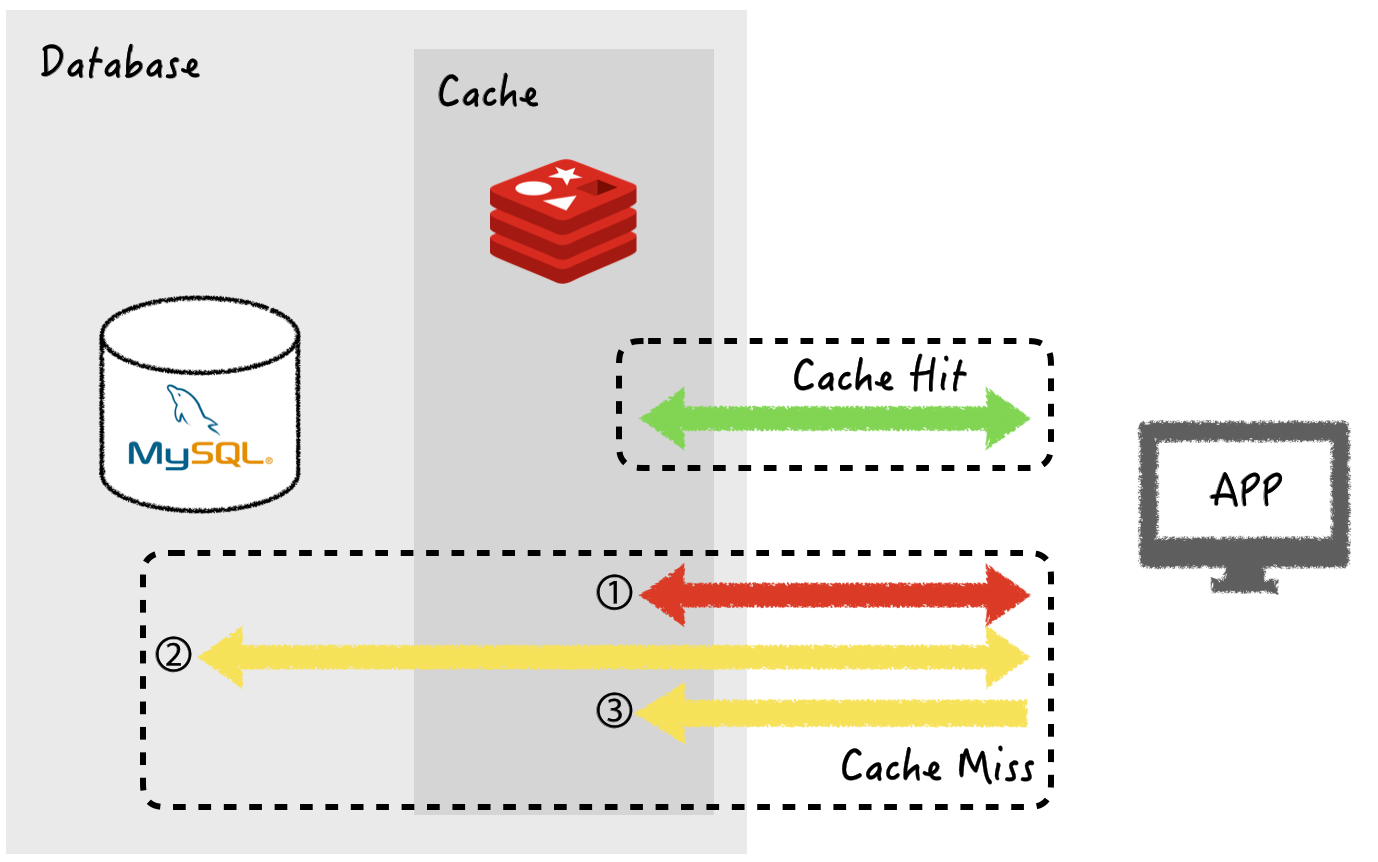
참고로 들어가기 앞서 선수 지식이 필요한데, 바로 cache hit 과 cache miss 이다.
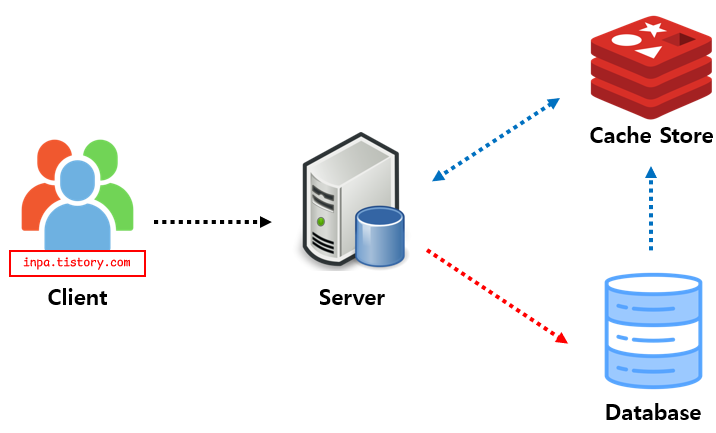
cache hit : 캐시 스토어(redis)에 데이터가 있을 경우 바로 가져옴 (빠름)
cache miss : 캐시 스토어(redis)에 데이터가 없을 경우 어쩔수없이 DB에서 가져옴 (느림)
캐싱 전략 패턴 종류
캐시를 이용하게 되면 반드시 닥쳐오는 문제점이 있는데 바로 데이터 정합성 문제이다.
데이터 정합성이란, 어느 한 데이터가 캐시(Cache Store)와 데이터베이스(Data Store) 이 두 곳에서 같은 데이터임에도 불구하고 데이터 정보값이 서로 다른 현상을 말한다.
쉽게 말하면, 캐시에는 어떤 게시글의 좋아요 갯수가 10개로 저장되어 있는데 데이터베이스에는 7개로 저장되어있을 경우 정보 불일치가 발생하게 된다.
이전에는 그냥 DB에서 데이터 조회와 작성을 처리하였기 때문에 데이터 정합성 문제가 나타나지 않았지만, 캐시라는 또다른 데이터 저장소를 이용하기 때문에, 결국 같은 종류의 데이터라도 두 저장소에서 저장된 갑시 서로 다를수 있는 현상이 일어날수 밖에 없는 것이다.
따라서 적절한 캐시 읽기 전략(Read Cache Strategy)과 캐시 쓰기 전략(Write Cache Strategy)을 통해, 캐시와 DB간의 데이터 불일치 문제를 극복하면서도 빠른 성능을 잃지 않게 하기 위해 고심히 연구를 할 필요가 있다.
캐시 읽기 전략 (Read Cache Strategy)
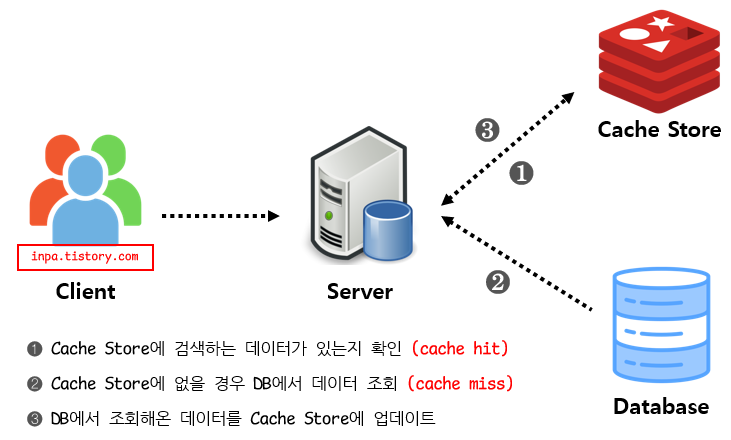
Look Aside 패턴
Cache Aside 패턴이라고도 불림.
데이터를 찾을때 우선 캐시에 저장된 데이터가 있는지 우선적으로 확인하는 전략. 만일 캐시에 데이터가 없으면 DB에서 조회함.
반복적인 읽기가 많은 호출에 적합.
캐시와 DB가 분리되어 가용되기 때문에 원하는 데이터만 별도로 구성하여 캐시에 저장
캐시와 DB가 분리되어 가용되기 때문에 캐시 장애 대비 구성이 되어있음. 만일 redis가 다운 되더라도 DB에서 데이터를 가져올수 있어 서비스 자체는 문제가 없음.
대신에 캐시에 붙어있던 connection이 많았다면, redis가 다운된 순간 순간적으로 DB로 몰려서 부하 발생.
Look Asdie Cache 패턴은 애플리케이션에서 캐싱을 이용할때 일반적으로 사용되는 기본적인 캐시 전략이다.
이 방식은 캐시에 장애가 발생하더라도 DB에 요청을 전달함으로써 캐시 장애로 인한 서비스 문제는 대비할수 있지만, Cache Store와 Data Store(DB)간 정합성 유지 문제가 발생할 수 있으며, 초기 조회 시 무조건 Data Store를 호출 해야 하므로 단건 호출 빈도가 높은 서비스에 적합하지 않다. 대신 반복적으로 동일 쿼리를 수행하는 서비스에 적합한 아키텍처이다.
이런 경우 DB에서 캐시로 데이터를 미리 넣어주는 작업을 하기도 하는데 이를 Cache Warming이라고 합니다.
[ Cache Warming ]
미리 cache로 db의 데이터를 밀어 넣어두는 작업을 의미한다. 이 작업을 수행하지 않으면 서비스 초기에 트래픽 급증시 대량의 cache miss 가 발생하여 데이터베이스 부하가 급증 할 수 있다. (Thundering Herd) 다만, 캐시 자체는 용량이 작아 무한정으로 데이터를 들고 있을수는 없어 일정시간이 지나면 expire되는데, 그러면 다시 Thundering Herd가 발생될 수 있기 때문에 캐시의 TTL을 잘 조정할 필요가 있다. (뒤에서 자세히 설명)
Thundering Herd는 모든 지점에서 발생되는 것은 아니고, 서비스의 첫 페이지와 같은 대부분의 조회가 몰리는 지점에서 주로 발생된다고 보면 된다.
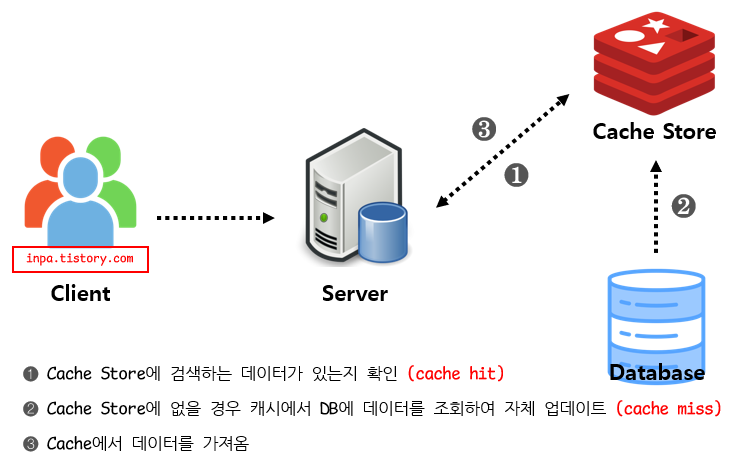
Read Through 패턴
캐시에서만 데이터를 읽어오는 전략 (inline cache)
Look Aside 와 비슷하지만 데이터 동기화를 라이브러리 또는 캐시 제공자에게 위임하는 방식이라는 차이가 있음.
따라서 데이터를 조회하는데 있어 전체적으로 속도가 느림.
또한 데이터 조회를 전적으로 캐시에만 의지하므로, redis가 다운될 경우 서비스 이용에 차질이 생길수 있음.
대신에 캐시와 DB간의 데이터 동기화가 항상 이루어져 데이터 정합성 문제에서 벗어날수 있음
역시 읽기가 많은 워크로드에 적합
Read Through 방식은 Cache Aside 방식과 비슷하지만,Cache Store에 저장하는 주체가 Server이냐 또는 Data Store 자체이냐에서 차이점이 있다.
이 방식은 직접적인 데이터베이스 접근을 최소화하고 Read 에 대한 소모되는 자원을 최소화할 수 있다.
하지만 캐시에 문제가 발생하였을 경우 이는 바로 서비스 전체 중단으로 빠질 수 있다. 그렇기 때문에 redis과 같은 구성 요소를 Replication 또는 Cluster로 구성하여 가용성을 높여야 한다.
이 방식 또한 서비스 운영 초반에 cache warming을 수행하는 것이 좋다.
캐시 쓰기 전략 (Write Cache Strategy)
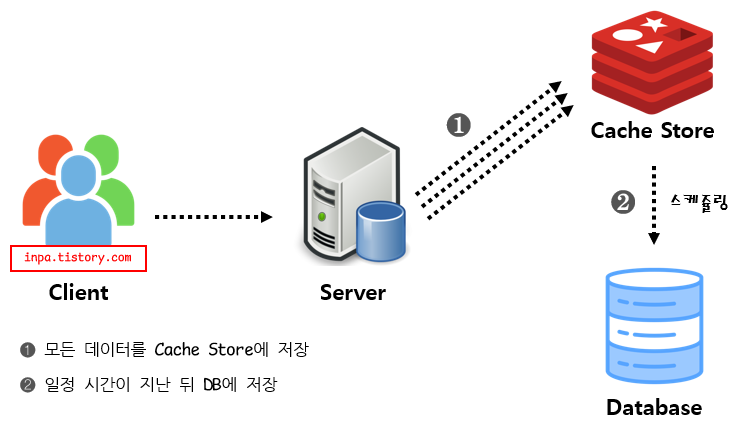
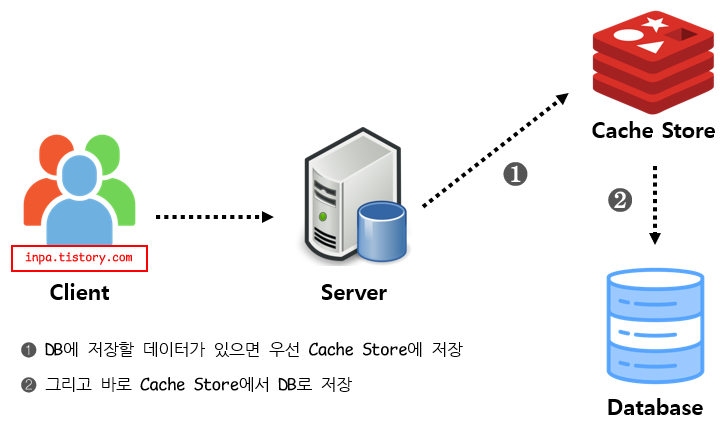
Write Back패턴
Write Behind 패턴 이라고도 불림.
캐시와 DB 동기화를 비동기하기 때문에동기화 과정이 생략
데이터를 저장할때 DB에 바로 쿼리하지않고, 캐시에 모아서 일정 주기 배치 작업을 통해 DB에 반영
캐시에 모아놨다가 DB에 쓰기 때문에 쓰기 쿼리 회수 비용과 부하를 줄일 수 있음
Write가 빈번하면서 Read를 하는데 많은 양의 Resource가 소모되는 서비스에 적합
데이터 정합성 확보
자주 사용되지 않는 불필요한 리소스 저장.
캐시에서 오류가 발생하면 데이터를 영구 소실함.
Write Back 방식은 데이터를 저장할때 DB가 아닌 먼저 캐시에 저장하여 모아놓았다가 특정 시점마다 DB로 쓰는 방식으로 캐시가 일종의 Queue 역할을 겸하게 된다.
캐시에 데이터를 모았다가 한 번에 DB에 저장하기 때문에 DB 쓰기 횟수 비용과 부하를 줄일 수 있지만, 데이터를 옮기기 전에 캐시 장애가 발생하면 데이터 유실이 발생할 수 있다는 단점이 존재한다. 하지만 오히려 반대로 데이터베이스에 장애가 발생하더라도 지속적인 서비스를 제공할 수 있도록 보장하기도 한다.
이 전략 또한 캐시에 Replication이나 Cluster 구조를 적용함으로써 Cache 서비스의 가용성을 높이는 것이 좋으며, 캐시 읽기 전략인 Read-Through와 결합하면 가장 최근에 업데이트된 데이터를 항상 캐시에서 사용할 수 있는 혼합 워크로드에 적합하다.
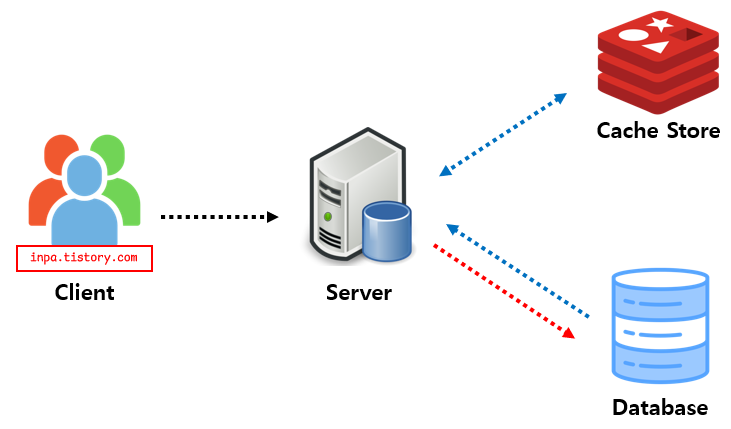
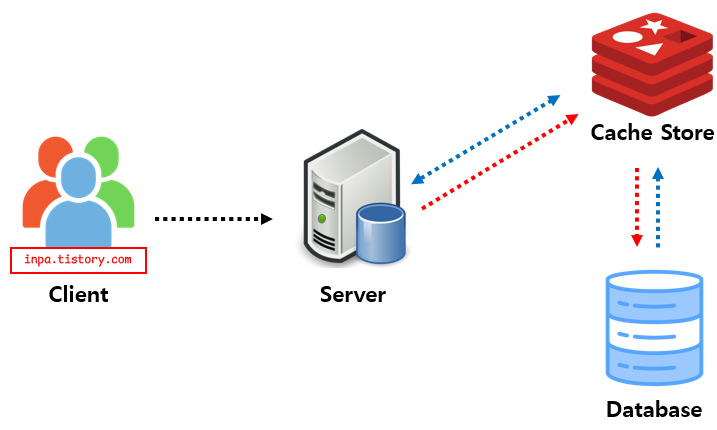
Write Through 패턴
데이터베이스와 Cache에 동시에 데이터를 저장하는 전략
데이터를 저장할 때 먼저 캐시에 저장한 다음 바로 DB에 저장 (모아놓았다가 나중에 저장이 아닌 바로 저장)
Read Through 와 마찬가지로 DB 동기화 작업을 캐시에게 위임
DB와 캐시가 항상 동기화 되어 있어,캐시의 데이터는 항상 최신 상태로 유지
캐시와 백업 저장소에 업데이트를 같이 하여 데이터 일관성을 유지할 수 있어서 안정적
데이터 유실이 발생하면 안 되는 상황에 적합
자주 사용되지 않는 불필요한 리소스 저장.
매 요청마다 두번의 Write가 발생하게 됨으로써 빈번한 생성, 수정이 발생하는 서비스에서는 성능 이슈 발생
기억장치 속도가 느릴 경우, 데이터를 기록할 때 CPU가 대기하는 시간이 필요하기 때문에 성능 감소
WriteThrough 패턴은Cache Store에도 반영하고 Data Store에도 동시에 반영하는 방식이다. (Write Back은 일정 시간을 두고 나중에 한꺼번에 저장)
그래서 항상 동기화가 되어 있어항상 최신정보를 가지고 있다는 장점이 있다.
하지만 결국 저장할때마다 2단계 과정을 거쳐치기 때문에 상대적으로 느리며, 무조건 일단 Cache Store에 저장하기 때문에 캐시에 넣은 데이터를 저장만 하고 사용하지 않을 가능성이 있어서 리소스 낭비 가능성이 있다.
write throuth 패턴과 write back 패턴 둘 다 모두 자주 사용되지 않는 데이터가 저장되어 리소스 낭비가 발생되는 문제점을 안고 있기 때문에, 이를 해결하기 위해 TTL을 꼭 사용하여 사용되지 않는 데이터를 반드시 삭제해야 한다. (expire 명령어)
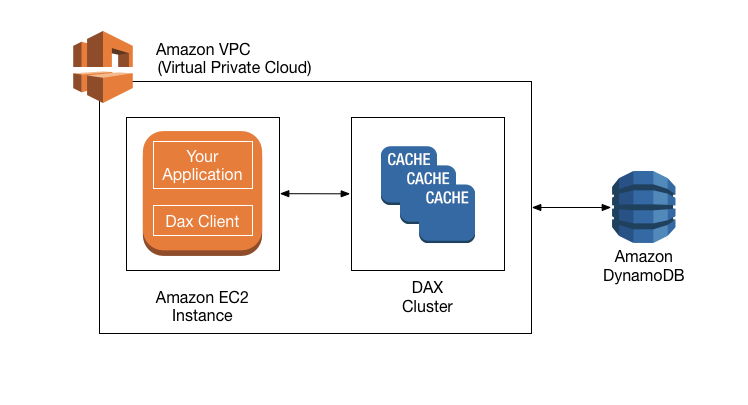
Write-Through 패턴과 Read-Through 패턴을 함께 사용하면, 캐시의 최신 데이터 유지와 더불어 정합성 이점을 얻을 수 있다. 대표적인 예로 AWS의 DynamoDB Accelerator(DAX)가 있다. DAX 패턴을 통해 DynamoDB에 대한 읽기 및 쓰기를 효율적으로 수행할 수 있다.
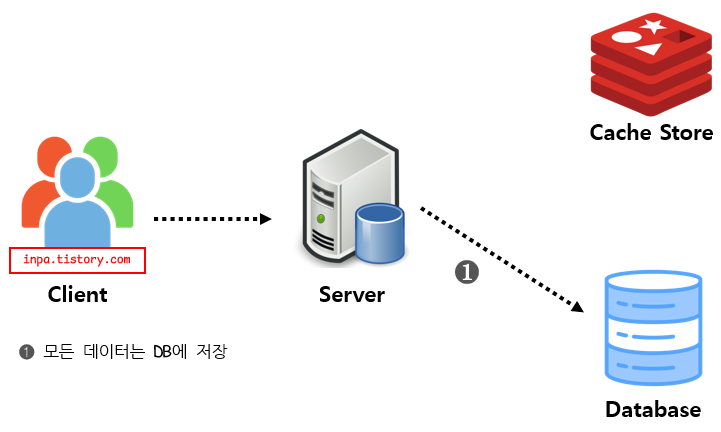
Write Around 패턴
Write Through 보다 훨씬 빠름
모든 데이터는 DB에 저장 (캐시를 갱신하지 않음)
Cache miss가 발생하는 경우에만 DB와 캐시에도 데이터를 저장
따라서 캐시와 DB 내의 데이터가 다를 수 있음 (데이터 불일치)
Write Around 패턴은 속도가 빠르지만, cache miss가 발생하기 전에 데이터베이스에 저장된 데이터가 수정되었을 때, 사용자가 조회하는 cache와 데이터베이스 간의 데이터 불일치가 발생하게 된다.
따라서 데이터베이스에 저장된 데이터가 수정, 삭제될 때마다, Cache 또한 삭제하거나 변경해야 하며, Cache의 expire를 짧게 조정하는 식으로 대처해야 한다.
Write Around 패턴은 주로 Look aside, Read through와 결합해서 사용된다. 데이터가 한 번 쓰여지고, 덜 자주 읽히거나 읽지 않는 상황에서 좋은 성능을 제공한다.
캐시 읽기 + 쓰기 전략 조합
Look Aside +Write Around 조합
가장 일반적으로 자주 쓰이는 조합
Read Through +Write Around 조합
항상 DB에 쓰고, 캐시에서 읽을때 항상 DB에서 먼저 읽어오므로 데이터 정합성 이슈에 대한 완벽한 안전 장치를 구성할 수 있음
Read Through +Write Through 조합
데이터를 쓸때 항상 캐시에 먼저 쓰므로, 읽어올때 최신 캐시 데이터 보장
데이터를 쓸때 항상 캐시에서 DB로 보내므로, 데이터 정합성 보장
캐시 저장 방식 지침
캐시 솔루션은 자주 사용되면서 자주 변경되지 않는 데이터의 경우 캐시 서버에 적용하여 반영할 경우 높은 성능 향상을 이뤄낼 수 있다. 이를 Cache Hit Rating이라고 한다.
일반적으로 캐시는 메모리에 저장되는 형태를 선호한다.
메모리 저장소로는 대표적으로 Redis와 MemCached가 있으며 이와 같은 솔루션은 메모리를 1차 저장소로 사용하기 때문에 디스크와 달리 제약적인 저장 공간을 사용하게 된다.
많아야 수십기가 정도의 저장소를 보유하게 되며, 이는 결국 자주 사용되는 데이터를 어떻게 뽑아 캐시에 저장하고 자주 사용하지 않는 데이터를 어떻게 제거해 나갈 것이냐를 지속적으로 고민해야 할 필요성이 있다.
따라서 캐시를 저장하는 시점은 자주 사용되며 자주 변경되지 않는 데이터를 기준으로하는 것이 좋다.
또한 한가지 고민해야 할 사항은 캐시 솔루션은 언제든지 데이터가 날라갈 수 있는 휘발성을 기본으로 한다는 점이다.
이는 데이터를 주기적으로 디스크에 저장함으로서 어느정도 해결을 볼수는 있지만, 실시간으로 모든 데이터를 디스크에 저장할 경우 성능 저하를 일으킬 수 있어 어느 정도 데이터 수집과 저장 주기를 가지도록 설계 해야 된다.
즉 데이터의 유실 또는 정합성이 일정 부분 깨질 수 있다는 점을 항상 고려해야 한다.
따라서캐시에 저장되는 데이터는 중요한 정보, 민감 정보 등은 저장하지 않는 것이 좋으며, 캐시 솔루션이 장애가 발생했을 경우 적절한 대응방안을 모색해 두는 것이 바람직하다. (TimeOut, 데이터베이스 조회 병행 등)
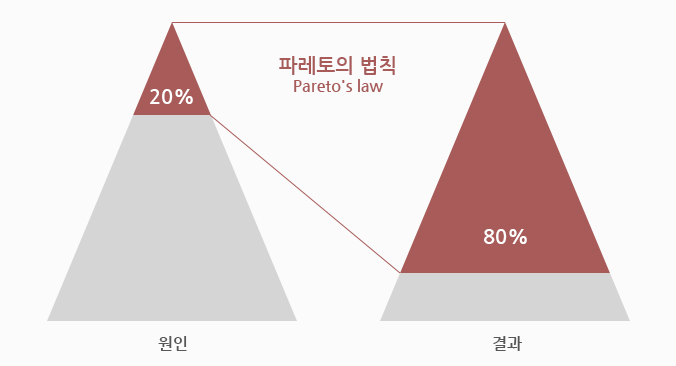
[ 파레토 법칙 - 8:2 법칙 ]
파레토 법칙이란 전체 결과의 80%가 전체 원인의 20%에서 일어나는 현상을 가리킨다. 서비스에 빗대어 표현하자면 80%의 활동을 20%의 유저가 하기 때문에 20%의 데이터만 캐시 해도 서비스 대부분의 데이터를 커버할 수 있게 된다는 말이다. 즉, 캐시에 모든 데이터를 저장할 필요 없이 "파레토 법칙"에 따라 일부만 저장해도 대부분의 데이터를 커버할 수 있다는 저장 지침이다.
캐시 제거 방식 지침
캐시 데이터의 경우 캐시 서버에만 단독으로 저장되는 경우도 있지만, 대부분 영구 저장소에 저장된 데이터의 복사본으로 동작하는 경우가 많다.
이는 2차 저장소(영구 저장소)에 저장되어 있는 데이터와 캐시 솔루션의 데이터를 동기화 하는 작업이 반드시 필요함을 의미하며, 개발 과정에 고려사항이 늘어난다는 점을 반드시 기억해야 한다.
예를 들어 캐시 서버와 데이터베이스에 저장되는 데이터의 commit 시점에 대한 고려 등이 예가 될 수 있다.
캐시의 만료 정책이 제대로 구현되지 않은 경우 클라이언트는 데이터가 변경되었음에도 오래된 정보가 캐싱 되어있어 오래된 정보를 사용할 수 있다는 문제점이 발생한다.
따라서 캐시를 구성할 때 기본 만료 정책을 설정해야 한다.
캐시된 데이터가 기간 만료 되면 캐시에서 데이터가 제거 되고, 응용 프로그램은 원래 데이터 저장소에서 데이터를 검색 해야 한다.
그래서 캐시만료 주기가 너무 짧으면 데이터는 너무 빨리 제거되고 캐시를 사용하는 이점은 줄어든다.
반대로 너무 기간이 길면 데이터가 변경될 가능성과 메모리 부족 현상이 발생하거나, 자주 사용되어야 하는 데이터가 제거되는 등의 역효과를 나타낼 수도 있다.
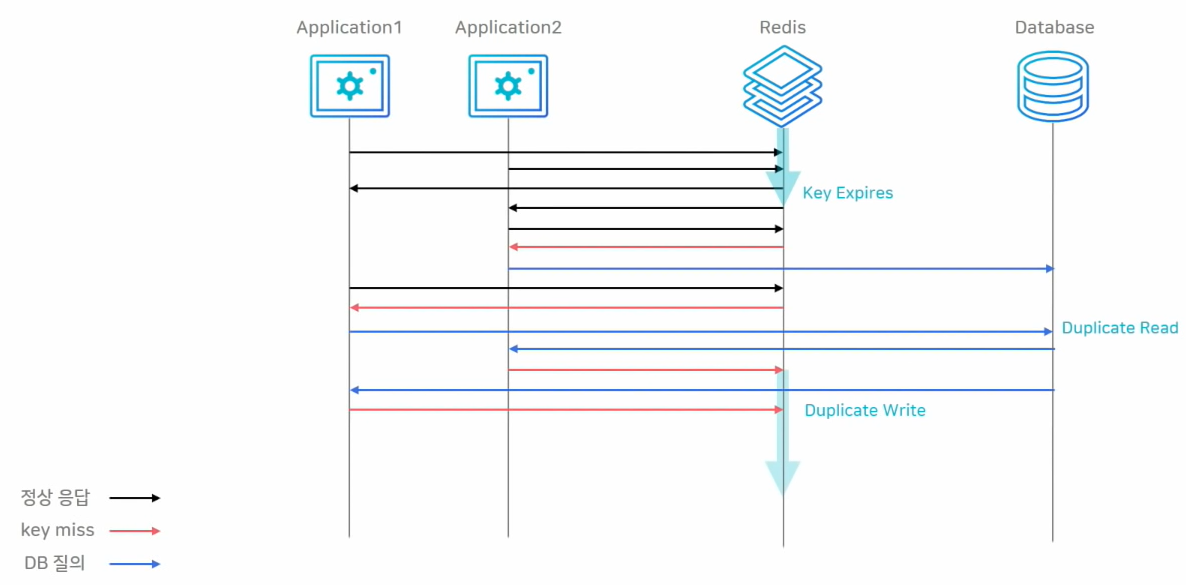
Cache Stampede 현상
대규모 트래픽 환경에서 TTL 값이 너무 작게 설정하면cache stampede 현상이 발생할 가능성이 있다.
위에서 배웠듯이 Look-aside 패턴에서 redis에 데이터가 없다는 응답을 받은 서버 (캐시 미스)가 직접 DB로 데이터 요청한 뒤, 다시 redis에 저장하는 과정을 거친다.
그런데 위 상황에서 key가 만료(Key Expires)되는 순간 많은 서버에서 이 key를 같이 보고 있었다면 모든 어플리케이션 서버에서 DB로 가서 찾게 되는duplicate read가 발생한다.
또 읽어온 값을 각 각 redis에 쓰는duplicate write도 발생되어, 처리량도 다 같이 느려질 뿐 아니라 불필요한 작업이 굉장히 늘어나 요청양 폭주로 장애로 이어질 가능성 도 있다.
캐시 공유 방식 지침
캐시는 애플리케이션의 여러 인스턴스에서 공유하도록 설계된다.
그래서 각 애플리케이션 인스턴스가 캐시에서 데이터를 읽고 수정할 수 있다.
따라서 어느 한 애플리케이션이 캐시에 보유하는 데이터를 수정해야 하는 경우, 애플리케이션의 한 인스턴스가 만드는 업데이트가 다른 인스턴스가 만든 변경을 덮어쓰지 않도록 해야 한다.
그렇지 않으면 데이터 정합성 문제가 발생하기 떄문이다. (각 애플리케이션 마다 표시되는 갯수가 달라지는 현상)
데이터의 충돌을 방지하기 위해 다음과 같은 어플리케이션 개발 방식을 취해야 한다.
먼저, 캐시 데이터를 변경하기 직전에 데이터가 검색된 이후 변경되지 않았는지 일일히 확인하는 방법이다.
변경되지 않았다면 즉시 업데이트하고 변경되었다면 업데이트 여부를 애플리케이션 레벨에서 결정하도록 수정해야 한다.
이와 같은 방식은 업데이트가 드물고 충돌이 발생하지 않는 상황에 적용하기 용이하다.
두번째로, 캐시 데이터를 업데이트 하기 전에 Lock을 잡는 방식이다.
이와 같은 경우 조회성 업무를 처리하는 서비스에 Lock으로 인한 대기현상이 발생한다.
이 방식은 데이터의 사이즈가 작아 빠르게 업데이트가 가능한 업무와 빈번한 업데이트가 발생하는 상황에 적용하기 용이하다.
캐시 가용성 지침
캐시를 구성하는 목적은 빠른 성능 확보와 데이터 전달에 있으며, 데이터의 영속성을 보장하기 위함이 아니라는 점을 기억하고 설계해야 한다.
데이터의 영속성은 기존 데이터 스토어에 위임하고, 캐시는 데이터 읽기에 집중하는 것이 성능 확보의 지침 사항이 될 수 있다.
또한, 캐시 서버가 장애로 인해 다운되었을 경우나 서비스가 불가능할 경우에도 지속적인 서비스가 가능해야 한다.
이는 캐시에 저장되는 데이터는 결국 기존 영구 데이터 스토어에 동일하게 저장되고 유지된다는 점을 뒷바침하는 설계방식이다. (Write Through)
즉, 캐시 서버가 장애로 부터 복구되는 동안 성능상의 지연은 발생할 수 있지만, 서비스가 불가능한 상태가 되지 않도록 고려해야 한다는 말이다.