...

몽고디비 관계 데이터 방식
몽고디비의 컬렉션간의 관계(조인) 데이터를 가져올때 대표적으로 2가지 방식 종류가 있다.
Document - Embedded
Embedded 저장 방법은 2가지 종류의 Document가 있을 때, 1개의 Document 데이터를 Document key의 value에 통짜로 저장하는 방법이다.
예를 들어, 여기 2가지 종류의 Person Document 와 Address Document가 있다고 하자.
// Person
{
_id: "joe",
name: "Joe Bookreader"
}// Address
{
pataron_id: "joe",
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
위의 Document를 Embedded 방식으로 관계를 저장하면 다음과 같이 된다.
Person.address 에 Address Document가 통째로 저장되어 있는 것을 볼 수 있다.
// Person
{
_id: "joe",
name: "Joe Bookreader",
address: { // Address
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
}Document - Reference
Reference 저장 방법은 pointer 개념으로 이해하면 된다.
Embedded 방식의 Document를 통째로 저장하는것이 아니라 참조 할 수 있도록 ID를 저장하는 방식이다.
예를들어, 2가지 종류의 Publisher Document / Book Document가 있을때, Book Document의 publisher_id 에 Publisher._id 의 value 를 저장하는 것이다.
RDBMS의 외래키와 같은 개념이라고 봐도 되며, 이렇게 _id를 저장해주면 몽고디비가 알아서 찾아 연결해준다.
// Publisher
{
_id: "oreilly", // <- Publisher._id
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
// Book
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly" // <- Publisher._id
}몽고디비 관계 유형
One-to-One 방식
단순한 1:1 관계이다.
RDBMS는 테이블을 나누어서 표현했지만, NOSQL은 하나의 다큐먼트에 그대로 표현이 가능하다.
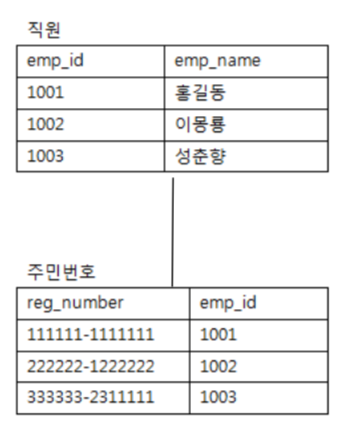
// 두개의 테이블로 나누어 1:1 관계를 맺는게 아니라, 몽고디비는 그냥 도큐먼트에 키값을 저장해버리면 된다.
{
"emp_id" : 1001,
"emp_name" : "홍길동",
"reg_number" : "111111-1111111"
}
One-to-Many 방식
1:N 관계 이며 여기서 위에서 배운 몽고디비 관계 데이터 2가지 방식에 따라 장단점이 갈리게 된다.
다음과 같이 1개의 Publisher Document 와 2개의 Book Document 가 있다고 가정하자.
Embedded 방식으로 했을 때,위에서 배운바와 같이 데이터 구조는 Book.publisher의 value 에 Publisher 데이터가 통째로 저장되게 된다.
가장 단순한 기법이지만 중복 데이터가 발생해 쓸데없이 도큐먼트 크기가 커진다는 단점이 있다.
/* *** Publisher 컬렉션 *** */
// Publisher 1 다큐먼트
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}/* *** Book 컬렉션 *** */
// Book 1 다큐먼트
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: { // 통째로 그대로 저장되어있다. 중복 발생
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
// Book 2 다큐먼트
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher: { // 통째로 그대로 저장되어있다. 중복 발생
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
반면 Reference 방식으로 했을 때는 2개의 Book.publisher_id 의 value 에 각각 Publisher._id의 value 만 저장되어 있게 된다.
/* *** Publisher 컬렉션 *** */
// Publisher 1 다큐먼트
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}/* *** Book 컬렉션 *** */
// Book 1 다큐먼트
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly" // <- Publisher._id
}
// Book 2 다큐먼트
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly" // <- Publisher._id
}
Many-to-Many
Many-to-Many 는 One-to-Many 관계에서 확장된 m:n 관계 유형이다.
One-to-Many 에서 Publisher : Book = 1 : n 이었지만, Many-to-Many 는 m : n 이 가능한 구조이다.
아래 예시를 보시면 Book.publisher_id value 가 1개 이상의 Publisher.id를 참조하고 있는걸 볼 수 있다.
/* *** Publisher 컬렉션 *** */
// Publisher 1 다큐먼트
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
// Publisher 2 다큐먼트
{
_id: "devhak",
name: "devhak'Reilly Media",
founded: 1980,
location: "CA"
}/* *** Book 컬렉션 *** */
// Book 1 다큐먼트
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: ["oreilly", "devhak"] // <- Publisher._id 여러개 참조
}
// Book 2 다큐먼트
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: ["oreilly", "devhak"] // <- Publisher._id 여러개 참조
}Embedded vs Reference 관계 장단점
이렇게 몽고디비의 관계 데이터 방식인 Embedded, Reference 방식과 1:1, 1:N, M:N 관계 형식을 살펴보았다.
그러면 어느 상황에서 어느 관계에서 어떤 방식을 사용해야 적절한지 살펴보자
먼저 One-to-Many(1:N) 관계에서 Embedded 와 Reference 방식을 각각 비교해보자.
만약 publisher 컬렉션에 ‘name’ 키를 변경하거나 ‘age’ 라는 키를 추가해야 하는 경우에 컬렉션 자체를 업데이트해야 되는데, 그러면 관계를 맺은 컬렉션 역시 수정을 해야 되는데 관계 데이터 방식에 따라 다르게 된다.
- Embedded 방식으로 저장된 데이터는 Publisher, Book 의 Document 를 모두 수정해서 데이터의 일관성을 유지해야 한다. 따라서 복잡하거나 데이터가 자주 변경되는 상황이 생긴다면 일관성을 유지하지가 어려워 질 수 있다.
- Reference 방식으로 저장된 데이터는 Publisher Document 만 수정해주면 어차피 ID만 참조하고 있기 때문에 모든 Document 는 수정할 필요가 없다. 자연스럽게 데이터의 일관성이 유지가 된다.
이렇게 보면 무조건 Reference 관계 데이터 방식이 효율적으로 보일수도 있겠지만, 반면에 이러한 가정도 있다.
다음과 같이 Document 마다 모두 관계가 저장되어 있다고 하자.
- Publisher Document 개수: 100개
- Book Document 개수: 100만개
극단적으로 100만개의 Book Document 를 Publisher 정보를 포함하여 불러오려고 할 때,
- Embedded 방식으로 저장된 데이터는 퍼포먼스 저하 없이 Publisher 정보를 통째로 가져올 수 있다.
- Reference 방식으로 저장된 데이터는 Publisher_id 에 해당되는 Publisher 정보를 포함하도록 요청해서 가져와야 하기 때문에 추가적인 요청을 해야만 Publisher 정보를 가져 올 수 있게 된다.
즉, 100만개의 Book Document를 조회해야한다면 100만번의 관계 포함 요청을 보내야 된다는 말과 같다.
당연히 이럴 경우 퍼포먼스 저하가 일어나게 된다.
따라서 정리하자면, Embedded 또는 Reference 둘 중 어떠한 저장 방법이 효율적일지는 서비스의 기획에 따라 달라지게 된다.
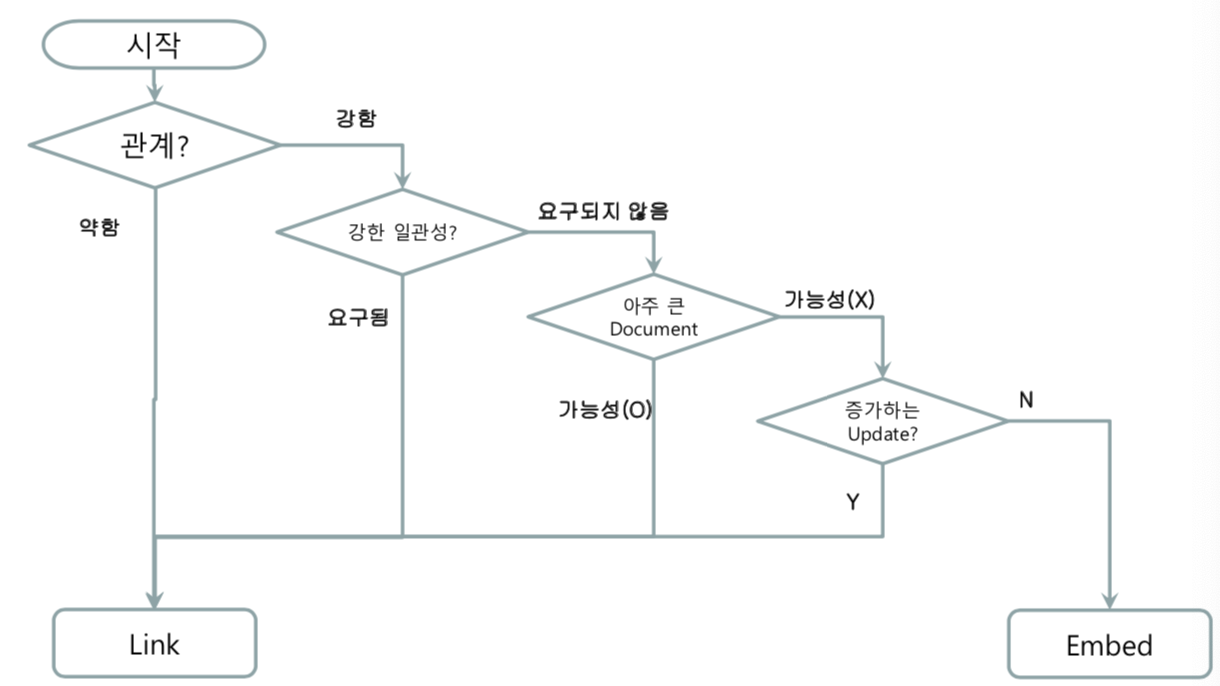
Embedded vs Reference 모델 특징
[Embedded 모델]
- 16MB 제한
- 빈번한 업데이트, 크기가 증가하는 업데이트일 때는 권장하지 않음 → 단편화
- 대신 읽기 속도 향상 : 한번의 쿼리로 조회
[Reference 모델]
- 더 복잡하지만 유연한 데이터 구조
- 데이터 크기 제한 없음
- 상대적으로 강한 일관성 제공 가능
이 글이 좋으셨다면 구독 & 좋아요
여러분의 구독과 좋아요는
저자에게 큰 힘이 됩니다.


