...

리눅스 파일 명령어
리눅스의 디렉토리 또한 일종의 파일이기 때문에, 디렉토리 명령어와 파일 명령어가 같이 사용되기도 한다.
파일 관리 명령어 종류
파일 정보 출력 (ls)
$ ls -al # : 파일의 상세정보
$ ls -t # : 파일들을 생성시간순(제일 최신 것부터)으로 표시
$ ls -F # : 파일 표시 시 마지막 유형에 나타내는 파일명을 끝에 표시 ('/' : 디렉터리, '*' : 실행파일, '@' : 링크 등등,,,)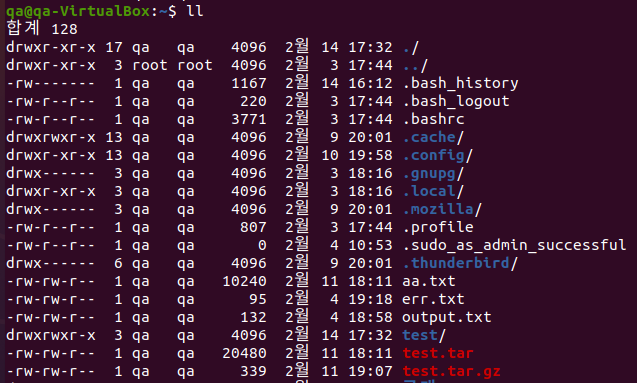

파일/디렉토리 복사 (cp)
# 파일을 복사해 새로운 파일 생성 가능
$ cp [복사대상] [새파일명]
# 파일을 디렉토리 안에 복사 가능
$ cp [복사대상] [디렉토리명]$ cp file1 file2 #: file1을 file2라는 이름으로 복사
$ cp -f file1 file2 #: 강제 복사(file2라는 파일이 이미 있을 경우 강제로 기존 file2를 지우고 복사 진행)
$ cp -r dir1 dir2 #: 디렉터리 복사. 폴더 안의 모든 하위 경로와 파일들을 복사| 옵션 | 설명 |
| -r, -R, --recursive | 디렉터리 내 파일과 디렉터리도 복사 (디렉토리 하위 파일들 싹 복사) |
| -i,--interactive | 존재 파일 덮어쓰기전에 사용자 확인받음. |
| -f,--force | 이미 존재하는 파일에 덮어쓸수 없는경우 해당파일 삭제후 다시 시도 |
| -b | 대상 파일이 이미 존재할때 기존 파일명 뒤에 ~붙여 백업 |
| -s,--symbolic-link | 파일 복사하는 대신 심볼릭 링크 생성. |
| -p | 허가권 소유권등을 보존하여 복사 |
| -v,--verbose | 항목 정보 상세 출력 |
| -d | 심볼릭 링크 자체 복사 |
| -a,--archive | 복사할대 원본파일이 갖고있는 모든 정보를 유지하여 복사 |
| -l,--link | 파일을 복사하지않고 하드링크 생성 |
| -u,--update | 원본파일이 대상파일보다 최신이거나 대상파일존재하지 않을때 복사 |
파일/디렉토리 삭제 (rm)
rmdir과 다르게 디렉토리 삭제 시 안에 파일이 존재해도 삭제 가능
$ rm file1 # : file1을 삭제
$ rm -f file1 # : file1을 강제 삭제
$ rm -i file1 # : 삭제하기전에 사용자 확인
$ rm -r dir # : dir 디렉터리 삭제 (디렉터리는 -r 옵션 없이 삭제 불가)
$ rm *[공통으로 끝나는 확장자] # : 공통으로 끝나는 확장자로 끝나는 파일 모두 삭제
$ rm * # : 모든 파일 삭제
파일/디렉토리 이동 (mv)
- 기본적으로 mv는 파일/디렉토리 이동
$ mv file1 /dir # : file1 파일을 dir 디렉터리로 이동
$ mv file1 file2 file3 /dir # : 여러 개의 파일을 dir 디렉터리로 이동
파일/디렉토리 이름변경 (mv)
- 단, 같은 디렉토리내에서, 파일 이동시 이름 변경 효과
# [같은 폴더에서 파일/디렉토리 이동시 이름 변경 효과]
$ mv file1 file2 # : file1 파일을 file2 파일로 이름 변경
$ mv /dir1 /dir2 # : dir1 디렉터리를 dir2 디렉터리로 이름 변경
빈 파일 생성 & 수정 날짜 변경 (touch)
- 기본적인 기능은 날짜 변경할 때 쓰이는 명령어
- 단, 존재하지 않는 파일이면, 파일크기가 0인 빈 새 파일 생성
- 디렉토리 생성 : $ mkdir
- 파일 생성 : $ touch / cat
- 만일 이미 존재하는 파일이라면, 최종 수정기간 변경
$ touch [option] filename
# -a : atime만 변경
# -m : mtime만 변경
# -t : 지정한 타임스탬프 설정
# -r, --reference : 현재시간이 아닌 지정한 파일의 타임스탬프로 변경
# -c, --no-create : 파일은 생성하지않음.$ touch filename # : filename의 파일을 생성
$ touch -c filename # : filename의 시간을 현재시간으로 갱신
$ touch -t 202110291608 filename # : filename의 시간을 날짜 정보(YYYYMMDDhhmm)로 갱신 (20211029160 => 2021.10.29.16:08)
$ touch -r oldfile newfile # : newfile의 날짜 정보를 oldfile의 날짜 정보와 동일하게 변경
파일 유형 확인 (file)
- 해당파일이 어떤 파일인지 표시, 텍스트 파일 (ASCII) 인지 실행 파일 (Executable) 인지 ..등
$ file [파일명]
# -b,--brief : 파일명은 출력하지않고 파일 유형만 출력
$ file test.txt
$ file /usr/bin/gzip
파일/디렉토리 검색 (find)
$ find [경로] [옵션] [표현식]
$ find [PATH] [OPTION] [EXPRESSION]
[OPTION]
-P : 심볼릭 링크를 따라가지 않고, 심볼릭 링크 자체 정보 사용.
-L : 심볼릭 링크에 연결된 파일 정보 사용.
-H : 심볼릭 링크를 따라가지 않으나, Command Line Argument를 처리할 땐 예외.
-D : 디버그 메시지 출력.
[EXPRESSION]
-name : 지정된 문자열 패턴에 해당하는 파일 검색.
-empty : 빈 디렉토리 또는 크기가 0인 파일 검색.
-delete : 검색된 파일 또는 디렉토리 삭제.
-exec : 검색된 파일에 대해 지정된 명령 실행.
-path : 지정된 문자열 패턴에 해당하는 경로에서 검색.
-print : 검색 결과를 출력. 검색 항목은 newline으로 구분. (기본 값)
-print0 : 검색 결과를 출력. 검색 항목은 null로 구분.
-size : 파일 크기를 사용하여 파일 검색.
-type : 지정된 파일 타입에 해당하는 파일 검색.
-mindepth : 검색을 시작할 하위 디렉토리 최소 깊이 지정.
-maxdepth : 검색할 하위 디렉토리의 최대 깊이 지정.
-atime : 파일 접근(access) 시각을 기준으로 파일 검색.
-ctime : 파일 내용 및 속성 변경(change) 시각을 기준으로 파일 검색.
-mtime : 파일의 데이터 수정(modify) 시각을 기준으로 파일 검색.# 현재 경로 하위 파일/디렉터리에서 [NAME]검색
$ find . -name [NAME]
# abc가 들어가는 디렉터리 모두 출력
$ find . -name '*abc*' -type d
# 디렉터리에 있는 c로 끝나는 확장자 파일을 10개만 먼저 출력
$ find /mollang '*.c' | head -10
# 수정한지 10일 이상된 파일만 뽑아서 자세히 출력
$ find . -mtime +10 -type f -ls
# 오래된 로그를 자동으로 정리해줄 때 잘 사용되는 명령어
# 수정한지 10일이 지난 오래된 tar파일들만 골라서 삭제
$ find . -name "*.tar" -mtime +10 -delete
# 파일 크기가 300KB 이상되는 파일만 출력
$ find . -size +300k
[LINUX] 📚 find 명령어 정복하기 [파일 검색]
파일/디렉토리 검색 find는 리눅스에서 파일 및 디렉토리를 검색할 때 사용하는 명령어다. $ find [경로] [옵션] [표현식] $ find [PATH] [OPTION] [EXPRESSION] find 명령에는 몇 가지 옵션과 많은 수의 표현식.
inpa.tistory.com
파일 내용(텍스트) 관련 명령어
파일 내용 전체 출력 (cat)
- ctrl + D 로 종료
$ cat file1 # : file1의 내용을 출력
$ cat file1 file2 # : file1과 file2의 내용을 출력
$ cat file1 file2 | more # : file1과 file2의 내용을 페이지별로 출력
$ cat file1 file2 | head # : file1과 file2의 내용을 처음부터 10번째 줄까지만 출력
$ cat file1 file2 | tail # : file1과 file2의 내용을 끝에서부터 10번째 줄까지만 출력
파일 내용 앞부분 출력 (head)
- 지정한 파일의 앞부분을 출력.
- 옵션을 지정하지 않으면 첫 10줄 출력
$ head [option] file
# -n,--lines : 출력할 줄 수를 지정
# -c,--byte : 출력한 바이트수를 지정
$ head -5 anaconda-ks.cfg # 앞에서 5행만 출력
파일 내용 뒷부분 출력 (tail)
- 지정한 파일의 끝 부분을 출력.
- 옵션을 지정하지 않으면 뒷 10줄 출력
$ tail [option] file
# -n,--lines : 파일의 마지막에서 지정한 줄만큼 출력
# -c,--bytes : 파일의 마지막에서 지정한 바이트 수만큼 출력
# -f,--follow : 새로운 데이터가 들어올때까지 모니터링
$ tail -5 anaconda-ks.cfg # 뒤에서 5행만 출력
파일 내용 페이지 단위로 출력 (more)
- 텍스트 형식의 파일을 페이지 단위로 출력
- space 누르면 다음페이지
- q 종료
| 단축키 |
설명
|
| Space |
다음 페이지로 이동
|
|
숫자 + z
|
숫자줄 만큼 다음으로 이동 |
|
q 또는Q
|
more 명령어 종료
|
| f |
다음 페이지로 이동
|
|
b
|
이전 페이지로 이동
|
|
=
|
현재 줄 번호 표시
|
| v |
vi 에디터로 실행
|
$ more [option] file
# -num : 스크린에 한번에 보여줄 줄수를 설정.
$ more +100 anaconda-ks.cfg # -> 100행부터 출력
파일 내용 페이지 단위로 출력 (less)
- more 에 pgUp pgDn 기능 추가 버젼
$ less [option] file
# -c,--clear-screen : 화면을 지우고 최상단부터 결과 출력
# -s--squeeze-blank-lines : 연속된 빈줄을 합쳐 하나의 빈줄로 만듬.
# -e : 파일 끝에서 한번 더 파일 끝으로 이동하면 자동으로 프로그램 종료.
# -N : 각줄마다 행 번호를 함께 출력
파일 패턴 검색 (grep)
- 텍스트 파일을 한줄씩 읽어서 지정한 패턴과 일치하는 문자열 보여주는 명령어
$ grep [OPTION] PATTERN [FILE]
-E : PATTERN을 확장 정규 표현식(Extended RegEx)으로 해석.
-F : PATTERN을 정규 표현식(RegEx)이 아닌 일반 문자열로 해석.
-G : PATTERN을 기본 정규 표현식(Basic RegEx)으로 해석.
-P : PATTERN을 Perl 정규 표현식(Perl RegEx)으로 해석.
-e : 매칭을 위한 PATTERN 전달.
-f : 파일에 기록된 내용을 PATTERN으로 사용.
-i : 대/소문자 무시.
-v : 매칭되는 PATTERN이 존재하지 않는 라인 선택.
-w : 단어(word) 단위로 매칭.
-x : 라인(line) 단위로 매칭.
-z : 라인을 newline(\n)이 아닌 NULL(\0)로 구분.
-m : 최대 검색 결과 갯수 제한.
-b : 패턴이 매치된 각 라인(-o 사용 시 문자열)의 바이트 옵셋 출력.
-n : 검색 결과 출력 라인 앞에 라인 번호 출력.
-H : 검색 결과 출력 라인 앞에 파일 이름 표시.
-h : 검색 결과 출력 시, 파일 이름 무시.
-o : 매치되는 문자열만 표시.
-q : 검색 결과 출력하지 않음.
-a : 바이너리 파일을 텍스트 파일처럼 처리.
-I : 바이너리 파일은 검사하지 않음.
-d : 디렉토리 처리 방식 지정. (read, recurse, skip)
-D : 장치 파일 처리 방식 지정. (read, skip)
-r : 하위 디렉토리 탐색.
-R : 심볼릭 링크를 따라가며 모든 하위 디렉토리 탐색.
-L : PATTERN이 존재하지 않는 파일 이름만 표시.
-l : 패턴이 존재하는 파일 이름만 표시.
-c : 파일 당 패턴이 일치하는 라인의 갯수 출력.# 특정 파일에서 'error' 문자열 찾기
$ grep 'error' 파일명
# 현재 디렉토리내에 있는 모든 파일에서 'error' 문자열 찾기
$ grep 'error' *
# 특정 확장자를 가진 모든 파일에서 'error' 문자열 찾기
$ grep 'error' *.log
# 특정 파일에서 a,b,c로 시작하는 단어를 모두 찾는다.
$ grep [a-c] 파일명
# 특정 파일에서 a나 b로 시작되는 모든 행을 찾는다.
$ grep '^[ab]' 파일명
# 특정 파일에서 여러개 문자열
$ cat mylog.txt | grep 'Apple' | grep 'Banana'# 실시간 로그 보기 (tail + grep)
$ tail -f mylog.log | grep 192.168.15.86[LINUX] 📚 정규표현식 과 grep 명령어 정복하기 [패턴 검색] [확장브래킷]
파일/디렉토리 패턴 검색 리눅스를 사용하다 보면 로그파일이나, 텍스트 파일에서 특정 문자열을 찾을 때, 혹은 디렉터리 내에서 특정 문자를 포함하는 파일을 찾을 때와 같은 경우가 생긴다.
inpa.tistory.com
파일 내용 정보 출력 (wc)
- 지정한 파일에 대해 단어, 개행문자, 문자의 개수 등을 출력
- 옵션 생략 시 줄, 단어, Bytes 수를 기본으로 출력
$ wc [option] file
# -l,--lines : 줄수를 셈
# -w,--words : 단어의 개수를 셈
# -c,--bytes : 바이트 수를 셈
# -L,--max-line-length : 가장 긴줄의 길이를 출력
파일 내용 정렬 (sort)
- 텍스트 파일을 한줄 씩 읽어서 한줄 씩 정렬
$ sort [옵션] [파일명]
# -r: 역순(내림차순) 정렬 / 기본은 오름차순
# -f: 대소문자 구별안함
# -n: 숫자로 정렬
# -k숫자: k1 -> 1번째 필드를 기준으로 정렬
# -u: 정렬 후 중복된 내용을 제거
# -b: 선행 공백 무시
# -R: 해시의 키값 기준, 랜덤 정렬
# -h: --human(2K, 1G)
# -c: 정렬되어 있는지 검사
# -m: 이미 정렬된 파일들을 병합
# -o: 파일출력
# -t: 필드 구분자를 지정# sort 명령어를 사용하면 오름차순으로 정렬된다.
$ sort sort.txt
# 다음과 같이 cat 명령어를 통해 파일을 열고 파이프를 통해 sort 명령어를 사용해도 된다.
# 위와 같은 결과 출력
$ cat sort.txt | sort
# -r 옵션으로 역순으로 정렬
$ sort -r sort.txt
$ cat sort.txt | sort -r
# -u 옵션으로 정렬 후 중복값 제거
$ sort -u sort3.txt
# -f 옵션으로 대소문자 구분 없이 정렬
# 대문자가 먼저 앞으로 온다
$ sort -f sort5.txt
# 파일이 정렬되어 있는지 검사
$ cat /etc/passwd | sort -c
# 정렬 후 파일로 저장
$ sort /etc/passwd -o output.txt # ls -l 한 디렉토리 정보 결과 출력내용을 파이프를 통해 정렬하는데 2번째 필드를 기준으로 역순 정렬
$ ll | sort -k2 -r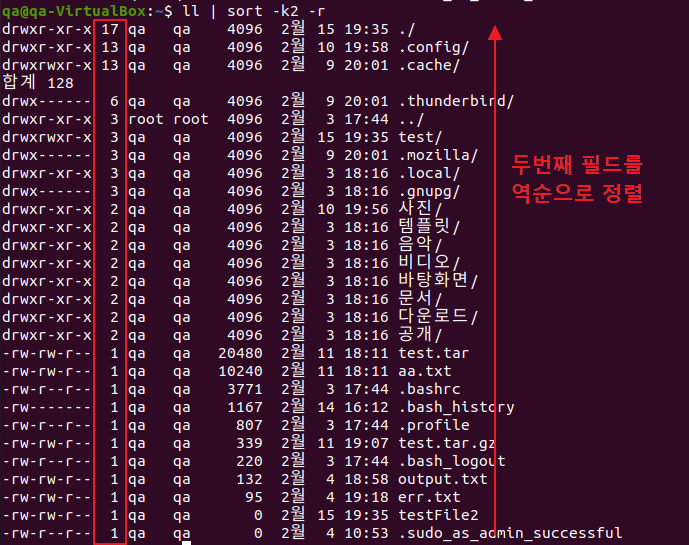
파일 내용 자르기 (cut)
- 파일에서 필드를 뽑아낸다.
- 필드는 구분자로 구분할 수 있다.
$ cut [option] file ...
# -c 문자위치 :잘라낼 곳의 글자 위치를 지정한다. 콤마나 하이픈을 사용하여 범위를 정할 수도 있으며, 이런 표현들을 혼합하여 사용할 수도 있다.
# -f 필드 : 잘라낼 필드를 정한다.
# -d 구분자 : 필드를 구분하는 문자를 지정한다. 디폴트는 탭 문자다.
# -s : 필드 구분자를 포함할 수 없다면 그 행은 하지 않는다.# /etc/passwd 내용 각 라인 문자열들을 ":" 기준으로 나누고 그중 첫번째 필드만 가져와라 (5줄만 출력)
cut -f1 -d ":" /etc/passwd | head -5
# 1 ~ 3 번째 필드를 가져오라
cut -f1-3 -d ":" /etc/passwd | head -5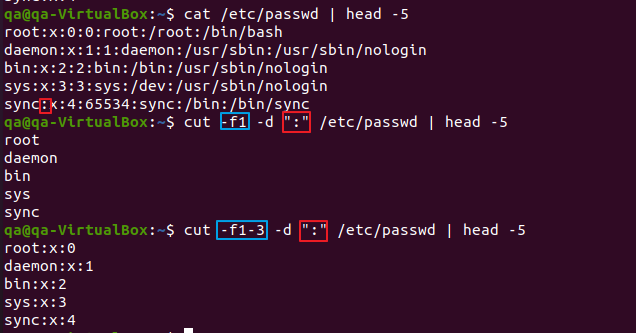
# 그냥 문자열 필드 1에서 4번째까지 문자만 골라 출력 (구분자 이런거 안하고)
$ cut -c1-4 /etc/passed | head -5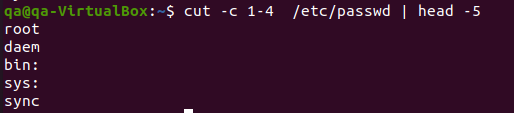
파일 나누기 (split)
- 큰 파일을 여러 작은 파일로 나눌때 사용
- 예를들어 로그 파일이 엄청 클때, split으로 파일을 분할 한 후 마지막 파일에선만 검색
$ split [option] file [file_name]
# -l : 라인수 기준으로 파일을 분할
# -b : 분할되는 기준을 바이트 크기로 분할
# -a : 분할되는 파일뒤에 붙을 길이를 지정
# -d : 분할 파일 이름뒤에 영문이 아닌 숫자로 지정 (0부터 시작)
# -n : 파일을 균등하게 1/N 나누어 분할
# -C : 라인을 기준으로 지정 바이트가 넘지 않도록 파일을 분할# 기본 1000줄씩 분할하여 파일 분할
$ split /etc/passwd # > 파일내용이 xaa, xab, xac ... 식으로 생성
# 10줄씩 분할하여 2.txt에 저장
$ split -l 10 /etc/passwd pass_ # > 파일내용이 pass_aa, pass_ab, pass_ac ... 식으로 생성
# 10줄씩 분할하여 2.txt에 저장
$ split -d -l 10 /etc/passwd pass_ # > 파일내용이 pass_00, pass_01, pass_02 ... 식으로 생성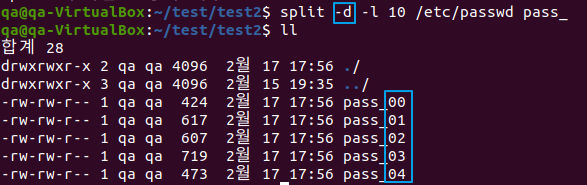
파일 합치기 (cat)
- split으로 나누었던 여러 파일들을 다시 하나로 합치기
- cat으로 간단하게 합치기 가능
# pass_00, 01 .. 로 나뉘어진 파일들을 pass.copy하나의 파일로 합치기 (오래걸려서 백그라운드로 작업 돌리기)
$ cat pass_* > pass.copy &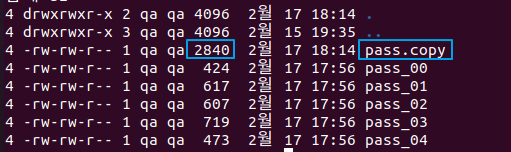
파일 비교 (cmp)
- 두파일이 다르면, 내용이 달라지기 시작하는 위치 (문자수, 줄수) 출력
- 완벽히 두개가 같으면 no 출력
| 옵션 | 설명 |
| -b | 두 파일간의 다른 바이트들을 출력 |
| -i | 입력어의 최초 SKIP 바이트들을 건너뛴다. |
| -l | 틀린 문자의 갯수를 출력 |
| -s | 아무것도 출력하지 않고 종료 코드만을 출력 0:파일이 같음, 1:파일이 다름, 2:파일에 접근 불가 |
| -v | 버전 정보 출력 |
$ cmp [파일1] [파일2]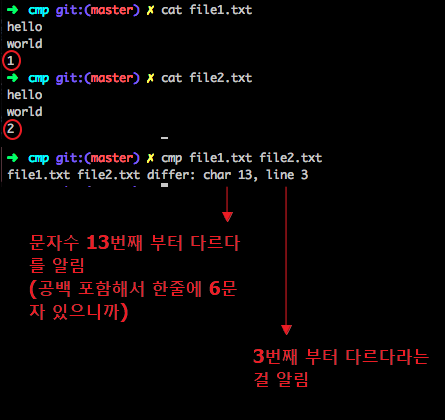
파일 비교 (diff)
- cmp와는 달리 두 파일을 비교하여 같아지는 조건 방침을 알려준다.
| 옵션 | 설명 |
| -c | 두 파일간의 차이점 출력 |
| -d | 두 파일간의 차이점을 상세하게 출력 |
| -r | 두 디렉터리간의 차이점 출력, 서브디렉터리까지 비교 |
| -i | 대소문자의 차이 무시 |
| -w | 모든 공백 차이 무시 |
| -s | 두 파일이 같을 때 알림 |
$ diff [파일1] [파일2]
$ diff3 [파일1] [파일2] [파일3] # 3개 파일 비교가 가능하다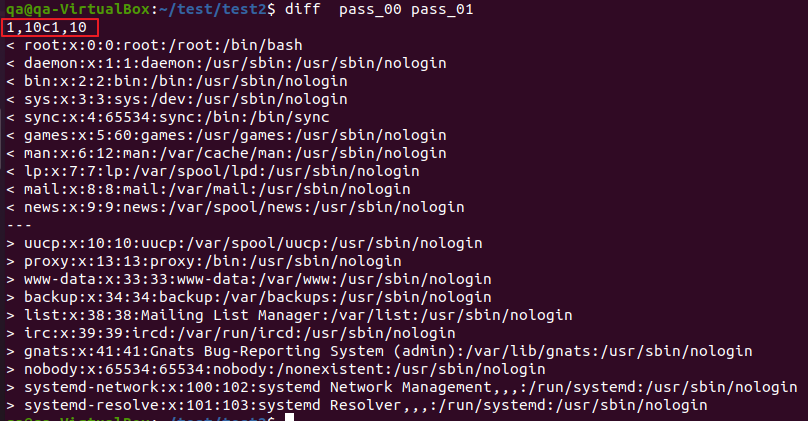
diff비교 해석
1,10a1,10 > [파일1] 1~10줄에 [파일2] 1~10번째 줄을 추가(add) 하면 두 파일은 같아진다.
10,13d9 > [파일1] 10~13줄을 삭제(delete) 하면, [파일2] 9줄 이후와 같아진다.
3,4c5,6 > [파일1] 3~4줄을, [파일2] 5~6;줄로 대체(change) 하면 두 파일이 같아진다.
# 참고자료
http://hansworld.co.kr/Instant_Backup/1261
https://www.putorius.net/linux-wc-command.html
https://laughcryrepeat.tistory.com/60
인용한 부분에 있어 만일 누락된 출처가 있다면 반드시 알려주시면 감사하겠습니다
이 글이 좋으셨다면 구독 & 좋아요
여러분의 구독과 좋아요는
저자에게 큰 힘이 됩니다.


