...

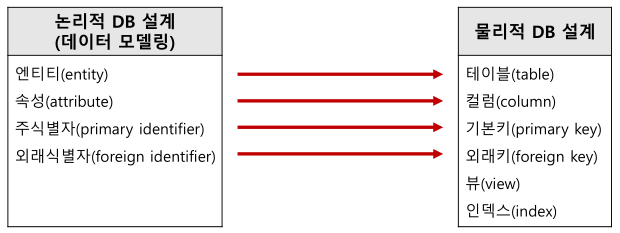
데이터 모델링 이란?
데이터 모델링이란 정보시스템 구축의 대상이 되는 업무 내용을 분석하여 이해하고 약속된 표기법에 의해 표현하는걸 의미한다. 그리고 이렇게 분석된 모델을 가지고 실제 데이터베이스를 생성하여 개발 및 데이터 관리에 사용된다.
특히 데이터를 추상화한 데이터 모델은 데이터베이스의 골격을 이해하고 그 이해를 바탕으로 SQL문장을 기능과 성능적인 측면에서 효율적으로 작성할 수 있기 때문에, 데이터 모델링은 데이터베이스 설계의 핵심 과정이기도 하다.
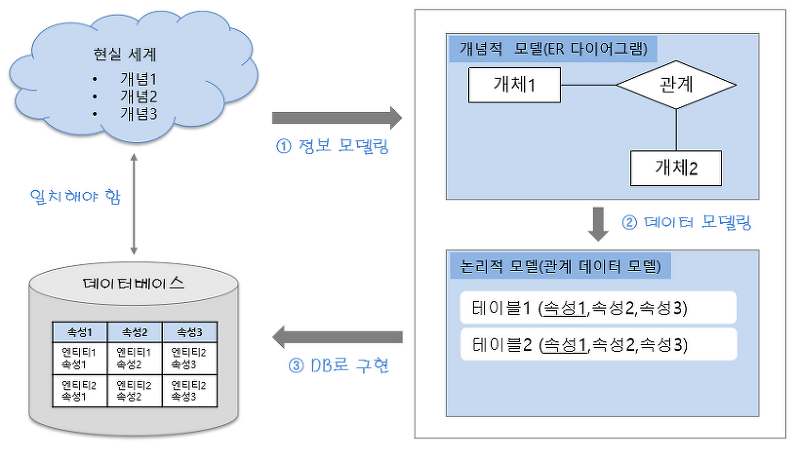
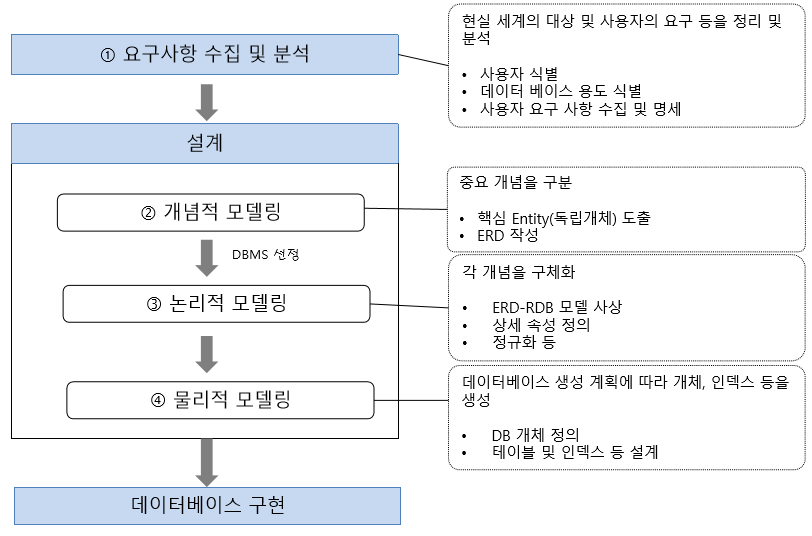
데이터 모델링 순서 절차
1. 업무 파악 (요구사항 수집 및 분석)
업무 파악은 어떠한 업무를 시작하기 전에 해당하는 업무에 대해서 파악하는 단계 이다.
모델링에 앞서 가장 먼저 해야 할 것은 어떠한 업무를 데이터화하여 모델링 할 것인지에 대한 요구사항 수집일 것이다. 업무파악을 하기 좋은 방법으로는 UI를 의뢰인과 함께 확인해 나아가는 는 것이다. 그리고 궁극적으로 만들어야 하는 것이 무엇인지 심도있게 알아보아야 한다.
이 포스팅에선 우리가 흔히 사용하는 게시판을 예를 들어보겠다.
2. 개념적 데이터 모델링
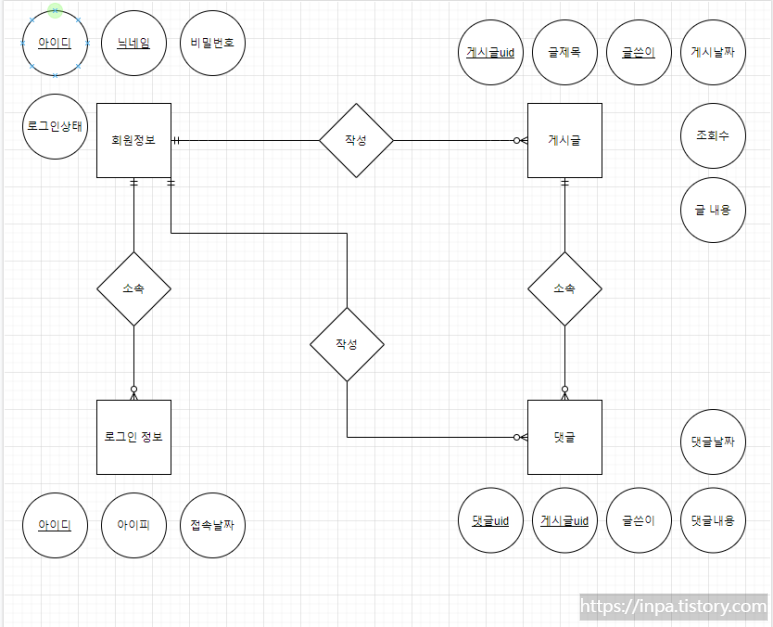
개념적 데이터 모델링은 내가 하고자 하는 일의 데이터 간의 관계를 구상하는 단계 이다. 각 개체들과 그들간의 관계를 발견하고 표현하기 위해 ERD 다이어그램을 생성한다.
다음은 피터 첸 표기법(Peter Chen Notation)으로 ERD 다이어그램을 구성한 그림이다. 그리는 방법은 어렵지 않다. 도형이 의미하는 바를 알고 화살표를 통해 관계를 표현하기만 하면 된다.
업무 파악 단계에서 결정했던 게시판 데이터 구상을 개념적 데이터 모델링으로 구현해본 것이다. 게시판에는 대표적으로 게시판 이용자의 회원 정보, 로그인 정보 그리고 게시판의 게시글, 댓글이 있다.
3. 논리적 데이터 모델링
개념적인 데이터 모델이 완성되면, 구체화된 업무 중심의 데이터 모델을 만들어 내는데, 이것을 논리적인 데이터 모델링이라고한다. 이 단계에서 업무에 대한 Key, 속성, 관계등을 표시하며, 정규화 활동을 수행한다. 정규화는 데이터 모델의 일관성을 확보하고 중복을 제거하여 신뢰성있는 데이터 구조를 얻는데 목적이 있다.
위에서 피터 첸 표기법으로 구현한 개념적 ERD 다이어그램을 정보 공학 표기법인 테이블 형태로 재 구성 한다.
이때 단순히 추상적인 데이터에서 보다 구체화적인 데이터로 작성한다. 예를 들어 회원정보의 아이디, 비밀번호에 각 데이터 타입을 명시해 주고 각 데이터간의 관계를 정밀하게 맺어주며 테이블의 키(key)를 지정해준다.
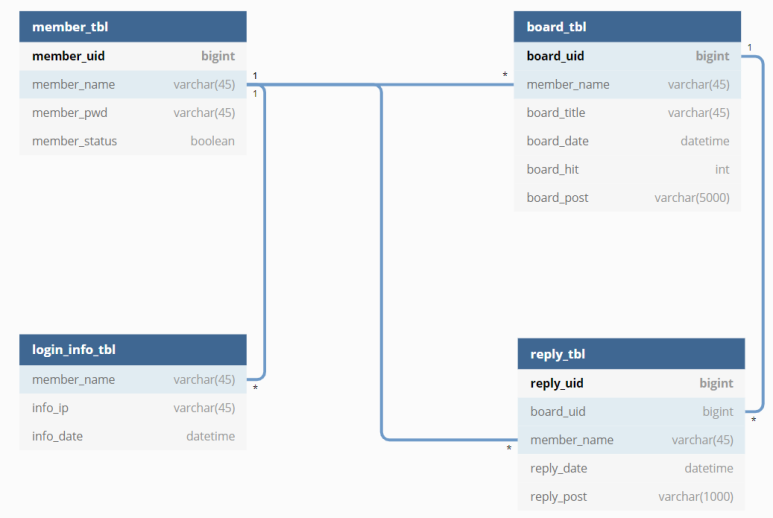
4. 물리적 데이터 모델링
물리적 데이터 모델링은 최종적으로 데이터를 관리할 데이터 베이스를 선택하고, 선택한 데이터 베이스에 실제 테이블을 만드는 작업 을 말한다. 시각적인 구조를 만들었으면 그것을 실제로 SQL 코딩을 통해 완성하는 단계라고 보면 된다
/* 테이블 생성 */
-- 회원정보
create table member_tbl (
member_uid bigint primary key auto_increment,
member_name varchar(45) unique not null,
member_pwd varchar(45) not null,
member_status boolean not null
);
-- 로그인기록정보
create table login_info_tbl(
member_name varchar(45) not null,
info_ip varchar(45) not null,
info_date datetime not null,
constraint fk_member_name foreign key (member_name) references member_tbl (member_name)
);
-- 게시판
create table board_tbl (
board_uid bigint primary key auto_increment,
member_name varchar(45) not null,
board_title varchar(45) not null,
board_date datetime not null,
board_hit int not null,
board_post varchar(5000) not null,
constraint fk_member_name foreign key(member_name) references member_tbl(member_name)
);
-- 게시판 풀텍스트 인덱스 생성
create Fulltext index idx_title on board_tbl ( board_title );
create Fulltext index idx_post on board_tbl ( board_post );
-- show index from board_tbl ;
-- 댓글
create table reply_tbl (
reply_uid bigint primary key auto_increment,
board_uid bigint not null,
member_name varchar(45) not null,
reply_date datetime not null,
reply_post varchar(1000) not null,
foreign key(board_uid) references board_tbl(board_uid),
foreign key(member_name) references member_tbl(member_name)
);
-- 댓글 풀텍스트 인덱스 생성
create Fulltext index idx_reply on reply_tbl ( reply_post );데이터 모델링 절차 정리
지금까지 알아보았던 절차를 간단하게 요약 정리하자면 다음과 같다.
- 네이버 게시판의 화면에 어떠한 것들이 필요한지에 대한 개념을 잡는게 업무파악 단계 (요구사항 수집 및 분석)
- 네이버 게시판의 화면에 표현되는 데이터들을 파악해서 관계를 설정하는게 개념적 데이터 모델링
- 개념적 데이터 모델링 한 것을 표로 만드는 게 논리적 데이터 모델링
- 이 일련의 과정을 수행한 것을, 실제 데이터베이스 테이블로 만드는 게 물리적 데이터 모델링
ERD (Entity Relationship Diagram) 그리기
ERD (Entity Relationship Diagram)는 단어에서 의미하는 그대로 'Entity 개체'와 'Relationship 관계'를 중점적으로 표시하는 데이터베이스 구조를 한 눈에 알아보기 위해 그려놓는 다이어그램이다. 개체 관계도라고도 불리며 요구분석사항에서 얻은 엔티티와 속성들의 관계를 그림으로 표현한 것이다.
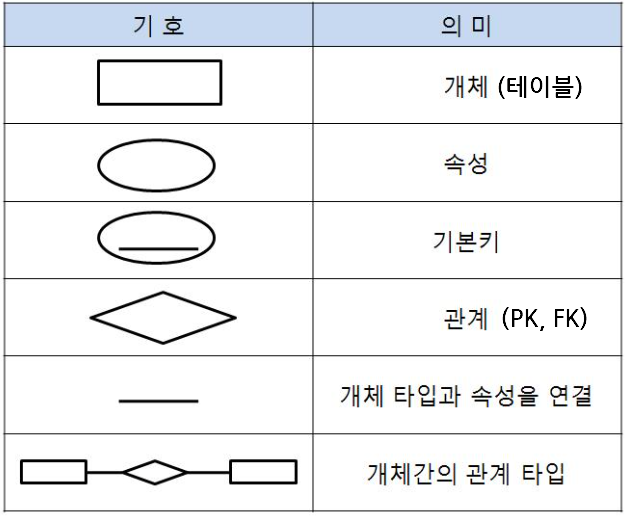
ERD 엔티티 표기법
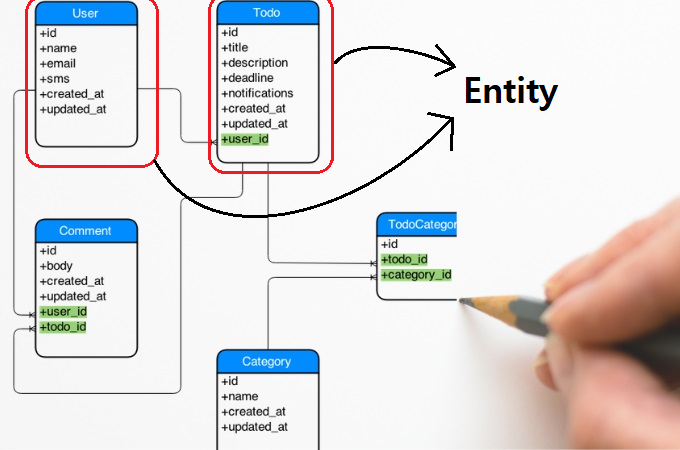
엔티티(Entity) 📄
- 엔티티는 정의 가능한 사물 또는 개념을 의미한다.
- 사람도 될수 있으며 프로필이나 도서정보와 같은 무형의 정보도 데이터화가 가능하다.
- 데이터베이스의 테이블이 엔티티로 표현된다고 보면 된다.
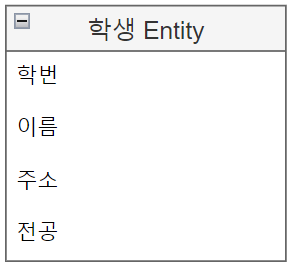
- 예를들어 학생 Entity는 아래의 그림과 같이 표현된다.

엔티티 속성(Attribute) 📑
- 엔티티에는 개체가 갖고있는 속성(Attribute)을 포함한다.
- 예를들어 학생 엔티티라면, 학번, 이름, 주소, 전공 ..등 속성들이 있다.
- 데이터베이스의 테이블의 각 필드(컬럼)들이 엔티티 속성이라고 보면 된다.
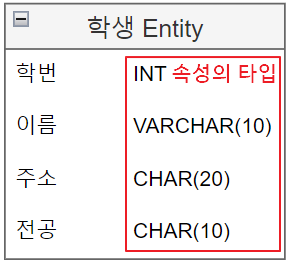
엔티티 도메인(Domain) 📝
- 도메인은 속성의 값, 타입, 제약사항 등에 대한 갑의 범위를 표현하는 것이다.
- 사용자 기호에 따라 속성 타입만 그릴수도 있고, 가독성을 위해서 생략할 수도 있다.
- 이때 데이터 타입을 명시할때, 데이터베이스가 지원하는 타입에 맞게 해야한다.
엔티티 분류 🧾
- 엔티티는 저장하는 데이터 정보 주제에 따라 종류가 다양하다.
- 고객 정보같은 실제로 물리적인 형태로 있는 정보와 구매 이력같은 무형적이고 개념적인 정보가 있다.
- 이 엔티티 분류 구분을 잘 해주어야 데이터베이스 설계에 있어 각 데이터 주제에 맞게 모델링을 구축할 수 있다.
| 구 분 | 내 용 |
| 유형 엔티티 | 물리적인 형태 (예 : 고객, 상품, 거래처, 학생, 교수 등) |
| 무형 엔티티 | 물리적인 형태가 없고 개념적으로만 존재하는 엔티티 (예 : 인터넷 장바구니, 부서 조직 등) |
| 문서 엔티티 | 업무 절차상에서 사용되는 문서나 장부, 전표에 대한 엔티티 (거래명세서, 주문서 등) |
| 이력 엔티티 | 업무상 반복적으로 이루어지는 행위나 사건의 내용을 일자별, 시간별로 저장하기 위한 엔티티 ( 예 : 입고 이력, 출고 이력, 구매 이력 등) |
| 코드 엔티티 | 무형 엔티티의 일종으로 각종 코드를 관리하기 위한 엔티티 (예 : 국가코드, 각종 분류 코드) |
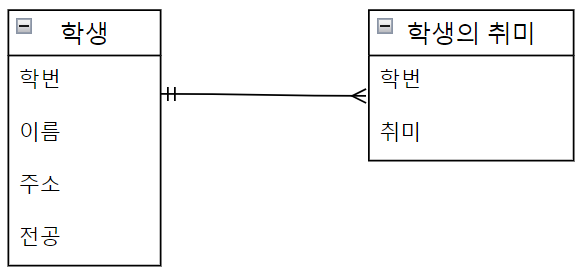
다음은 위에서 만든 학생 엔티티에 학생별 취미를 표현하는 엔티티를 추가하였다. 학생 엔티티는 유형 엔티티에 속하여, 학생별 취미는 무형 엔티티에 속하게 된다.

ERD 키와 제약 조건 표기법
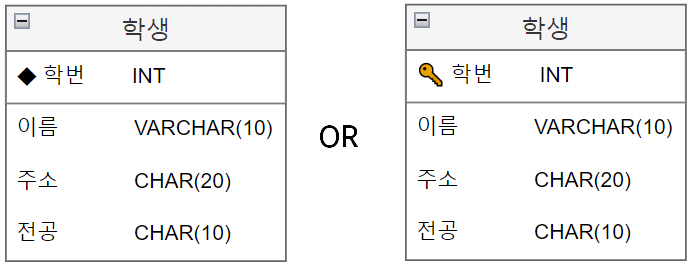
주 식별자 (PK) 🔑
- 데이터베이스 테이블의 Primary Key를 표현
- 중복이 없고 NULL 값이 없는 유일한 값에 지정하는 식별자
- 아래 그림과 같이 ◆ 다이아몬드로 표현하기도 하고 아니면 열쇠로도 표현하기도 한다.
- 그리고 주 식별자는 유일한 속성이므로 다른 속성과의 명확한 구분을 위해 구분선을 두기도 한다.
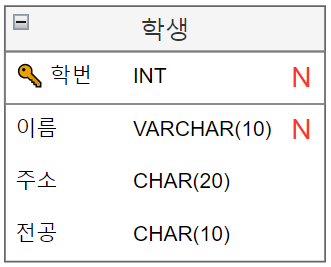
NOT NULL ❌
- 해당 속성에 들어갈 값에 Null 을 비허용한다면, N 혹은 NN을 적는다.
- 만일 Null 허용한다면 N을 적지 않는다.
외래 식별자 (FK) 🗝️
- 데이터베이스 테이블의 Foreign Key를 표현
- 외래 식별자 역시 key의 일종이라 ERD 엔티티에도 열쇠 아이콘으로 표시한다. (프로그램에 따라 다를 수 있다)
- 외래 식별자를 표시할 때에는 선을 이어주는데 개체와 관계를 따져 표시한다.
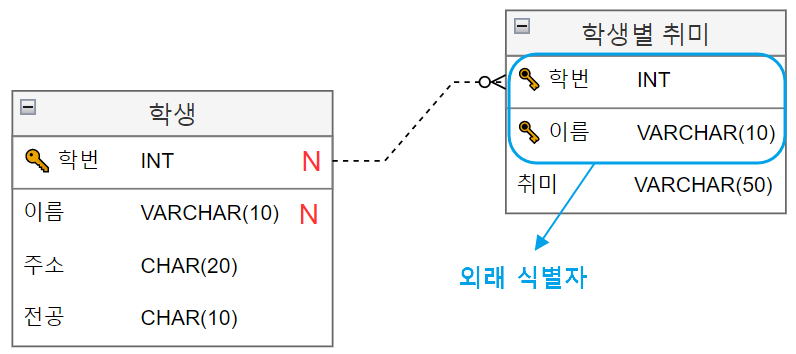
ERD 엔티티 관계 표기법
각 엔티티 유형들을 만들었으면, 엔티티 끼리 관계가 있는 경우 선을 이어 관계를 맺어야 한다. 엔티티 끼리 관계 선을 그을때 실선으로 그을지 점선으로 그을지 나뉘는데, 두 엔티티 관계에서 부모의 키를 자식에서 PK로 사용하는지 일반 속성으로 사용하지에 따라서 표기가 다르게 된다.
실선으로 그으면 강한 관계를 나타내는 것이며 '식별자 관계'라고 불리우며, 점선으로 그으면 약한 관계를 나타내는 것이며 '비식별자 관계'라고 불리우게 된다.
| 항목 | 식별자 관계 | 비식별자 관계 |
| 목적 | 강한 연결관계 표현 | 약한 연결관계 표현 |
| 자식 주식별자 영향 |
자식 주식별자의 구성에 포함됨 | 자식 일반 속성에 포함됨 |
| 표기법 | 실선 표현 | 점선 표현 |
| 연결 고려사항 |
- 반드시 부모엔터티 종속 - 자식 주식별자구성에 부모 주식별자포함 필요 - 상속받은 주식별자속성을 타 엔터티에 이전 필요 |
- 약한 종속관계 - 자식 주식별자구성을 독립적으로 구성 - 자식 주식별자구성에 부모 주식별자 부분 필요 - 상속받은 주식별자속성을 타 엔터티에 차단 필요 - 부모쪽의 관계참여가 선택관계 |
.
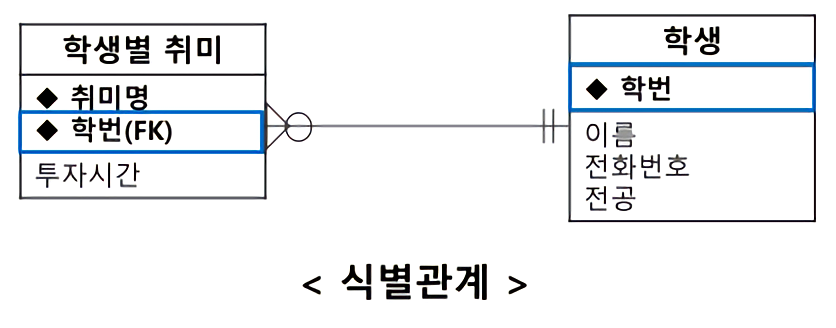
식별자 관계 ✍🏻
- 실선으로 표현
- 부모 자식 관계에서 자식이 부모의 주 식별자를 외래 식별자로 참조해서 자신의 주 식별자로 설정
- 아래 그림에선 자식 엔티티(학생별 취미)가 부모 엔티티(학생)의 학번을 자신의 주 식별자로 설정하였다.
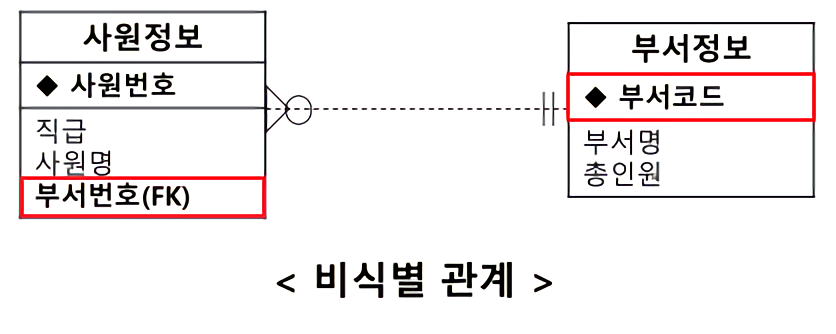
비식별자 관계 ✍🏻
- 점선으로 표현
- 부모 자식 관계에서 자식이 부모의 주 식별자를 외래 식별자로 참조해서 일반 속성으로 사용.
- 아래 그림에선 자식 엔티티(사원정보)가 부모 엔티티(부서정보)의 부서코드를 일반 속성으로 두었다.
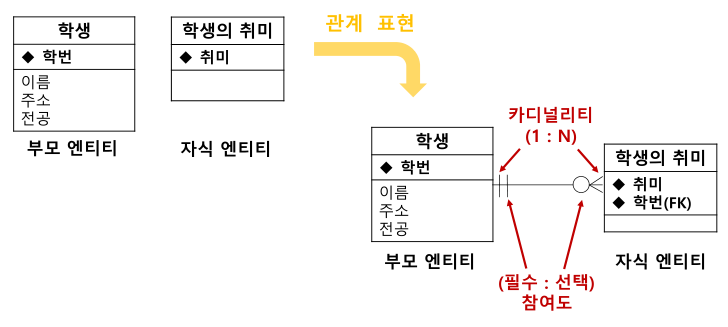
ERD 관계의 카디널리티
관계가 존재하는 두 entity사이에 한 entity에서 다른 entity 몇개의 개체와 대응되는지 제약조건을 표기하기위해 선을 그어 표현한다. 대표적으로 Mapping Cardinality의 종류는 다음과 같다.
Cardinality는 한 개체에서 발생할 수 있는 발생 횟수를 정의하며, 다른 개체에서 발생할 수 있는 발생 횟수와 연관된다.
- One to one : 1 대 1 대응
- One to many : 1 대 다 대응
- Many to one : 다 대 1 대응
- Many to many : 다 대 다 대응
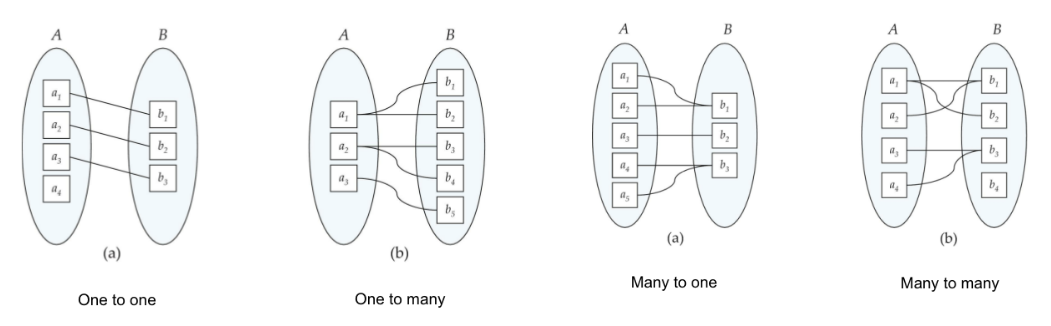
하지만 ERD 다이어그램에 위와같이 선 들을 막 긋는다면 가독성이 매우 안좋아지고 표가 더러워지기 때문에, 이러한 엔티티간의 1 대 다의 관계를 표기 하기 위해 ERD에서는 선의 끝 모양을 다르게 표시하는 방법을 사용한다.
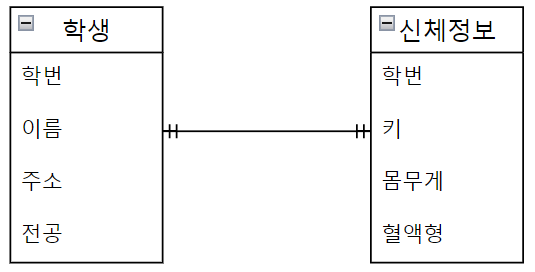
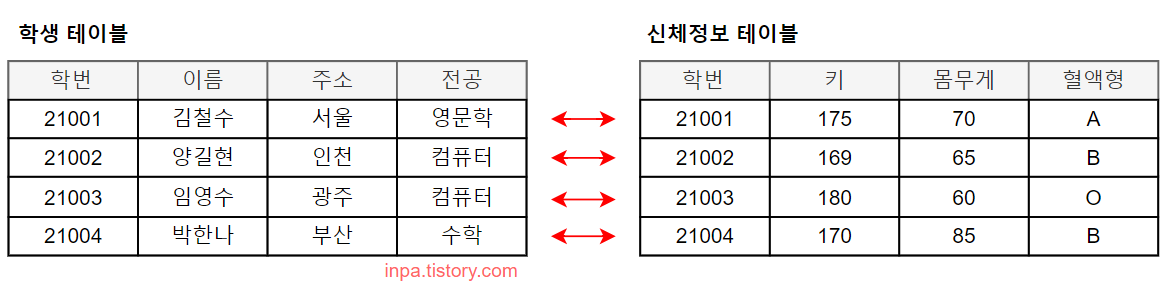
One-to-One Cardinality (1:1 관계)
- 학생가 신체정보는 1:1로 매칭된다.
- 한명의 학생은 하나의 신체정보를 갖기 때문이다.
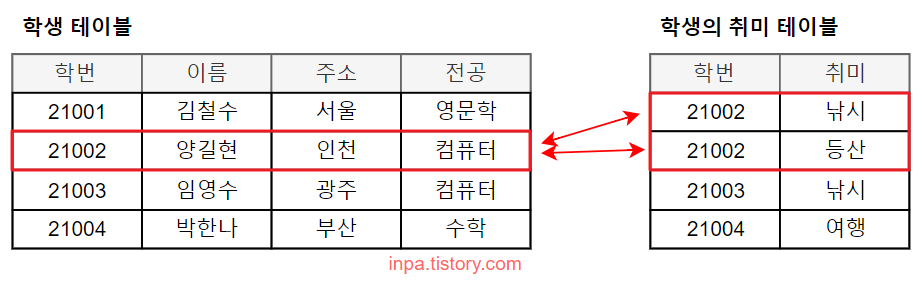
One-to-Many Cardinality (1:N 관계)
- 한명의 학생은 여러개의 취미를 가질수도 있다.
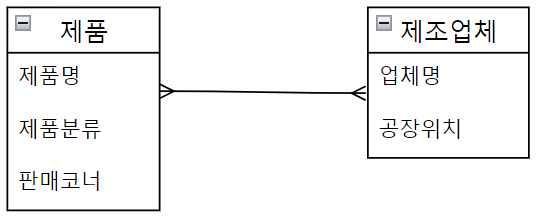
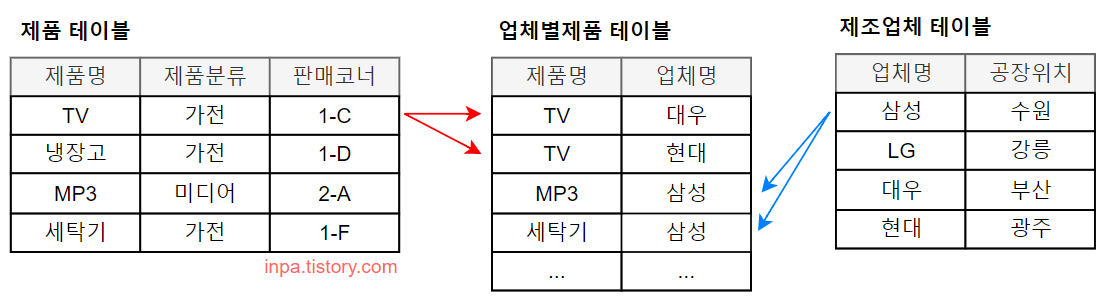
Many-to-Many Cardinality (M:N 관계)
- 제품 엔티티 입장에서, TV 제품은 대우 티비, 삼성 티비, 애플 티비 같은 여러 제조업체 제품이 있을 수 있다.
이는 냉장고나 세탁기도 마찬가지이다. 여러 기업에서 자신 만의 상표를 생산한다. - 제조업체 엔티티 입장에서, 삼성 제조업체는 세탁기만 생산하는게 아니라 MP3도 같이 생산한다.
실제로 삼성이나 애플 회사는 가전제품, 스마트폰, 전자기기 등 여러 종류의 제품을 생산한다. - 따라서 제품과 제조업체 관계는 다 대 다 관계 된다.
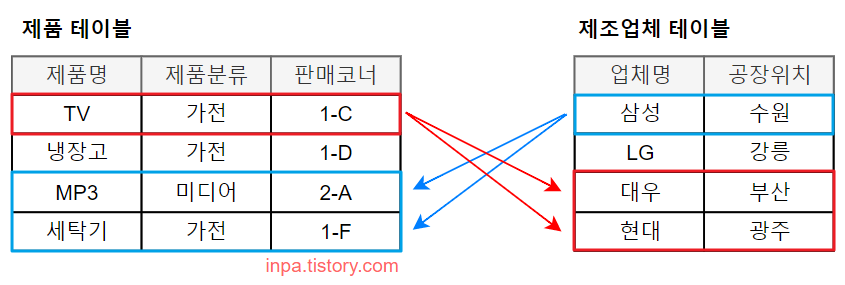
Many-to-Many Cardinality 관계의 해소
- 그런데 두 엔티티가 다 대 다 관계에 있는 경우, 두개의 엔티티만으로는 서로를 표현하는데 부족하다.
- 데이터 모델링에서는 M:N 관계를 완성되지 않은 모델로 간주하여, 두 엔티티의 관계를 1:N, N:1 로 조정하는 작업이 필요하다.
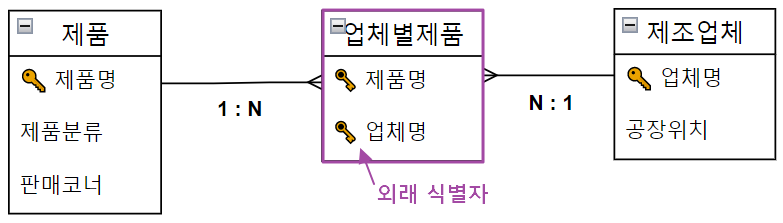
- 따라서 두 엔티티의 관련성을 표현하기 위해서는 중간에 또 다른 엔티티를 필요로 한다. 이 중간 엔티티(업체별 제품)가 두 엔티티의 공유 속성 역할을 하게 된다.
- 이 부분은 데이터 모델링에서 공식 처럼 적용되는 규칙이며, ERD 프로그램에서 M:N을 잡게 된다면 자동으로 아래와 같이 조정 작업이 행해지게 된다.
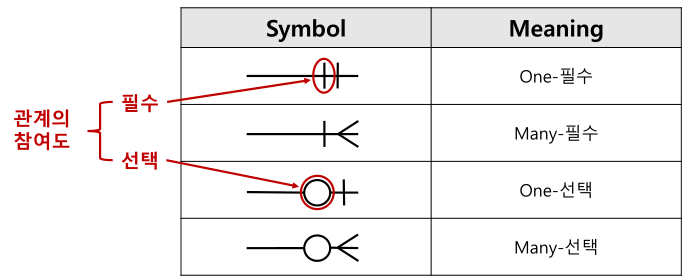
ERD 관계의 참여도
- 관계선 각 측의 끝자락에 기호를 표시한다.
- '|' 표시가 있는 곳은 반드시 있어야 하는 개체. (필수)
- 'O' 표시가 있다면 없어도 되는 개체. (선택)
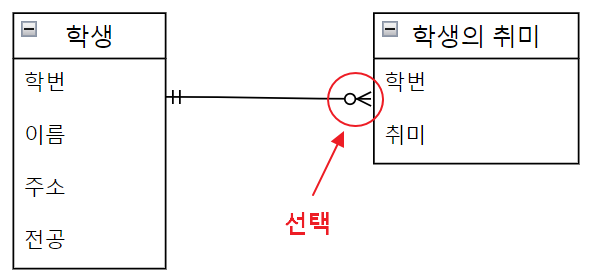
관계의 선택 기호 🚩
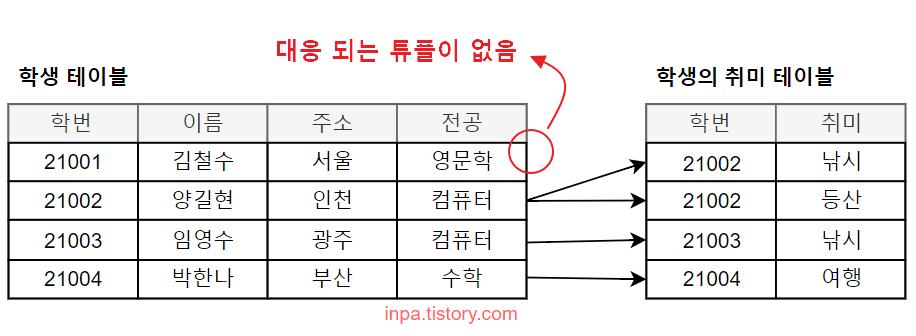
- 취미를 가진 학생이 있을수도 있고, 취미가 없는 학생이 있을 수도 있다.
- 김철수 학생은 게임이 취미라서, 대응되는 학생의 취미 테이블에 없기 때문에 관계가 없다. (선택)
- 대응 되는 인스턴스가 있을 수도 있고 없을 수도 없을 때 선택 관계 기호를 사용한다.
관계의 필수 기호 🚩
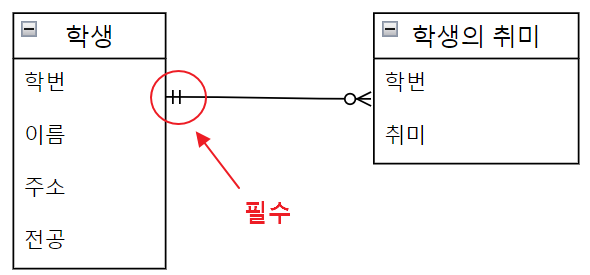
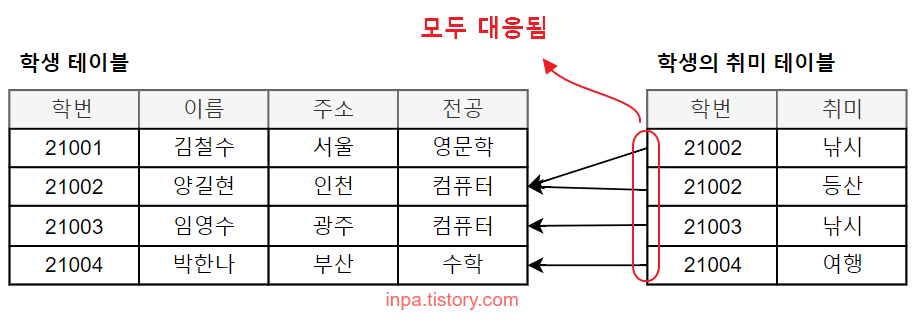
- 학번 21003 학생의 취미가 낚시 라는 정보가 있다면, 21003학번의 학생의 정보가 학생 엔티티에 반드시 존재해야 한다. (필수)
- 따라서 학생의 취미 테이블은 모두 학생 테이블에 대응된다.
- 어떤 학생이 어떤 취미를 갖는데 그 학생이 존재하지 않는다면 뭔가 잘못된 것이 된다.
- 이와 같이 어느 한 쪽이 존재하면 다른 쪽도 반드시 존재해야 하는 관계를 필수 관계 기호를 사용한다.
ERD 엔티티 관계 표현 총정리

1 : 1 관계 : 부모(SHOP)는 하나의 자식(FOOD)이 있다.
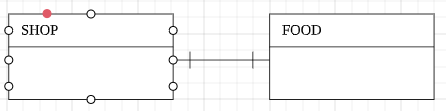
1 : N 관계 : 부모(SHOP)는 하나 이상의 자식(FOOD)이 있다.
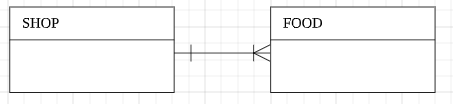
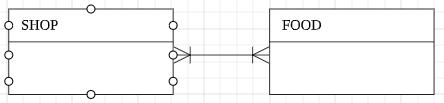
M : N 관계 : 하나 이상의 부모와 하나 이상의 자식이 있다.
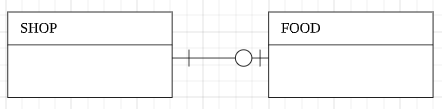
1 : 1(o) 관계 : 부모는 하나의 자식이 있을 수도 있다. (없을 수도 있다)
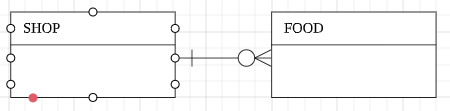
1 : N(o) 관계 : 부모는 여러개의 자식이 있을 수도 있다. (없을 수도 있다)
ERD 연습 예제 - 도서 관리 시스템
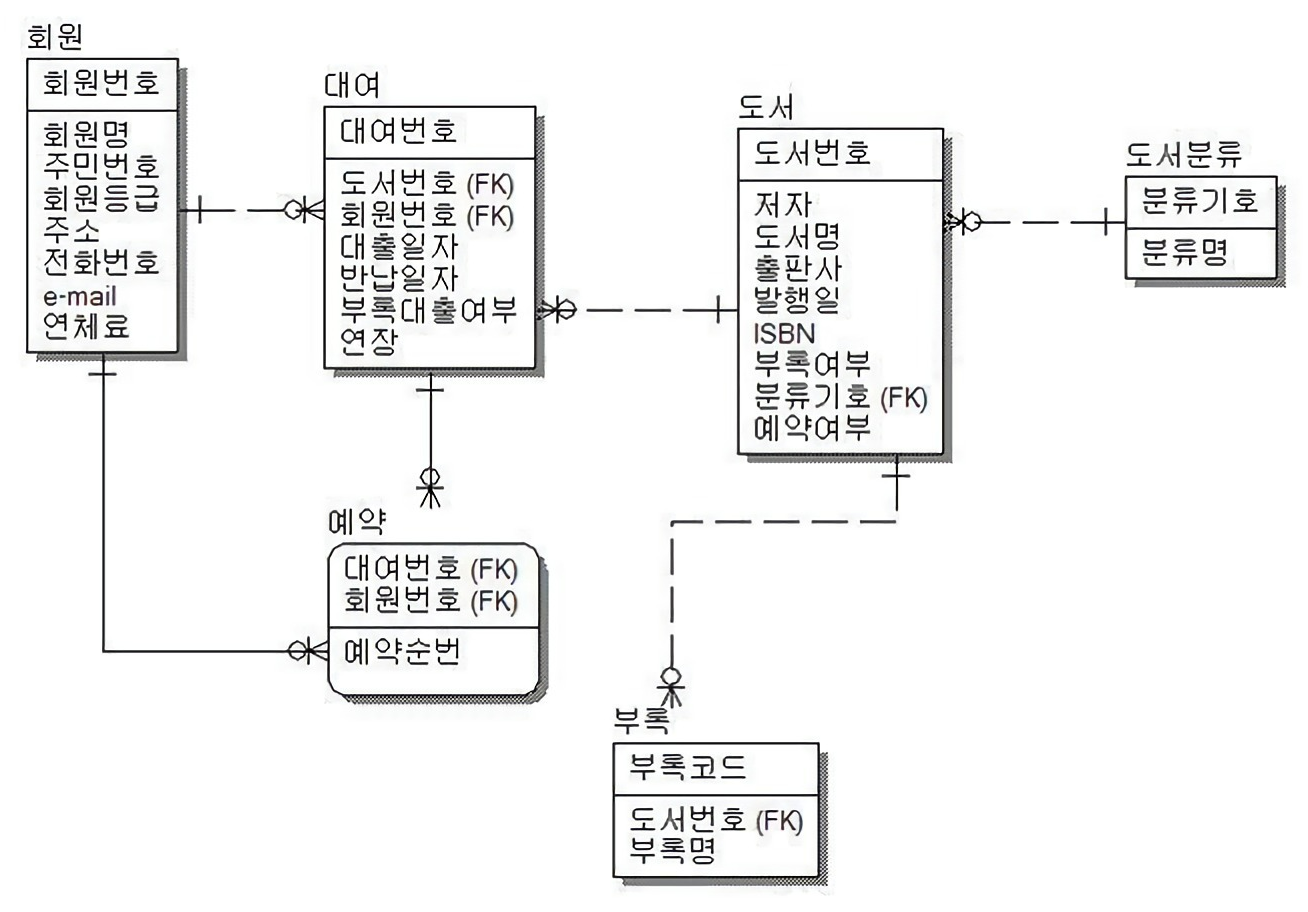
[회원 ↔ 대여]
- 회원번호PK가 대여 테이블에서 FK로 일반속성으로 쓰이고 있다. ( 점선 )
- 회원은 대여를 여러개 할 수 있다. ( 1:N )
- 아예 대여하지 않은 회원이 있을 수 있다. ( 1:N(선택) )
- 대여를 할땐 반드시 회원 정보가 필수로 존재해야한다. ( 1[필수]:N[선택] )
[도서 ↔ 대여]
- 도서번호PK가 대여 테이블에서 FK로 일반속성으로 쓰이고 있다. ( 점선 )
- 도서가 과거에 여러번 대여된 기록이 있을 수 있으니. ( 1:N )
- 아예 대여하지 않은 도서가 있을 수 있다. ( 1:N[선택] )
- 대여를 할땐 반드시 도서 정보가 필수로 존재해야한다. ( 1[필수]:N[선택] )
[회원 ↔ 예약]
- 회원번호PK가 예약 테이블에서 FK이자 PK로 쓰이고 있다. ( 실선 )
- 회원은 예약을 여러개 할 수 있다. ( 1:N )
- 아예 예약하지 않은 회원이 있을 수 있다. ( 1:N[선택] )
- 예약을 할땐 반드시 회원 정보가 필수로 존재해야한다. ( 1[필수]:N[선택] )
효율적인 모델링 작업하기
위의 도서 관리 모델링은 사실 잘못된 구조이다.
도서 Entity 같은 경우, 도서관의 같은 책(책 이름이 똑같은)이 있다는 가정하에 모델링을 했지만 여기엔 큰 허점이 존재한다. 왜냐하면 도서번호로 같은 책이 있더라도 번호를 달리해 구분은 가능할지 몰라도, 똑같은 자료를 중복하게되는 구조여서 결과적으로 데이터공간을 낭비하는 결과를 초래하기 때문이다.
따라서 도서관의 실제도서를 나타내는 Entity와 실제도서의 속성을 정의하는 Entity를 구분해야 된다. 도서번호만 다른 똑같은 책인 속성 정보가 완전히 같기 때문에, 아래 사진에서 볼수 있듯이 같은 도서의 속성들의 데이터가 중복으로 저장됨을 표로 볼 수 있다.
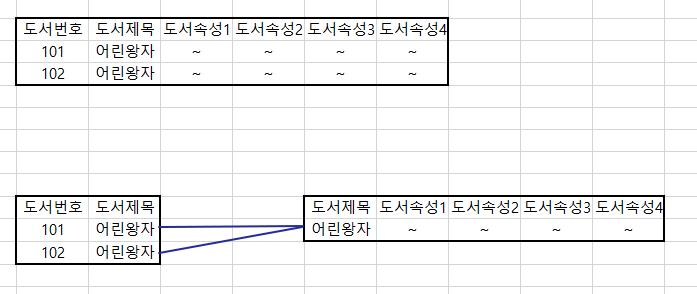
따라서 이 속성정보를 중복해서 한 테이블에 저장하는 것보다, 테이블을 따로 분리해서 속성을 따로 저장하는게 데이터공간을 절약할 수 있게 된다. 이러한 분담 행위를 정규화라고 하는데 자세한 원리는 다음 포스팅을 참고바란다.
[DB] 📚 제 1-2-3 정규화 & 역정규화 💯 정리
정규화란? ERD내에서 중복요소를 찾아 제거해 나가는 과정 - 중복된 데이터는 많은 문제를 일으킨다. 3차 정규화 정도만 알면 설계하는데 무리가 없다. - 중복을 최소화 -> 완전히 없애는게 아
inpa.tistory.com
수정된 도서 관리 시스템 ERD
도서 엔티티를 분리해, 도서와 도서정보로 쪼개고 이를 연결한다. 그리고 ISBN(국제표준도서번호)을 외래키로 설정해 관계를 구성한다. 그리고 추가적으로 예약 엔티티는 직관적이게, 대여에 연결하는게 아니라, 회원과 도서를 연결하는게 맞다. 따라서 도서 엔티티에 예약 엔티티를 연결해준다.
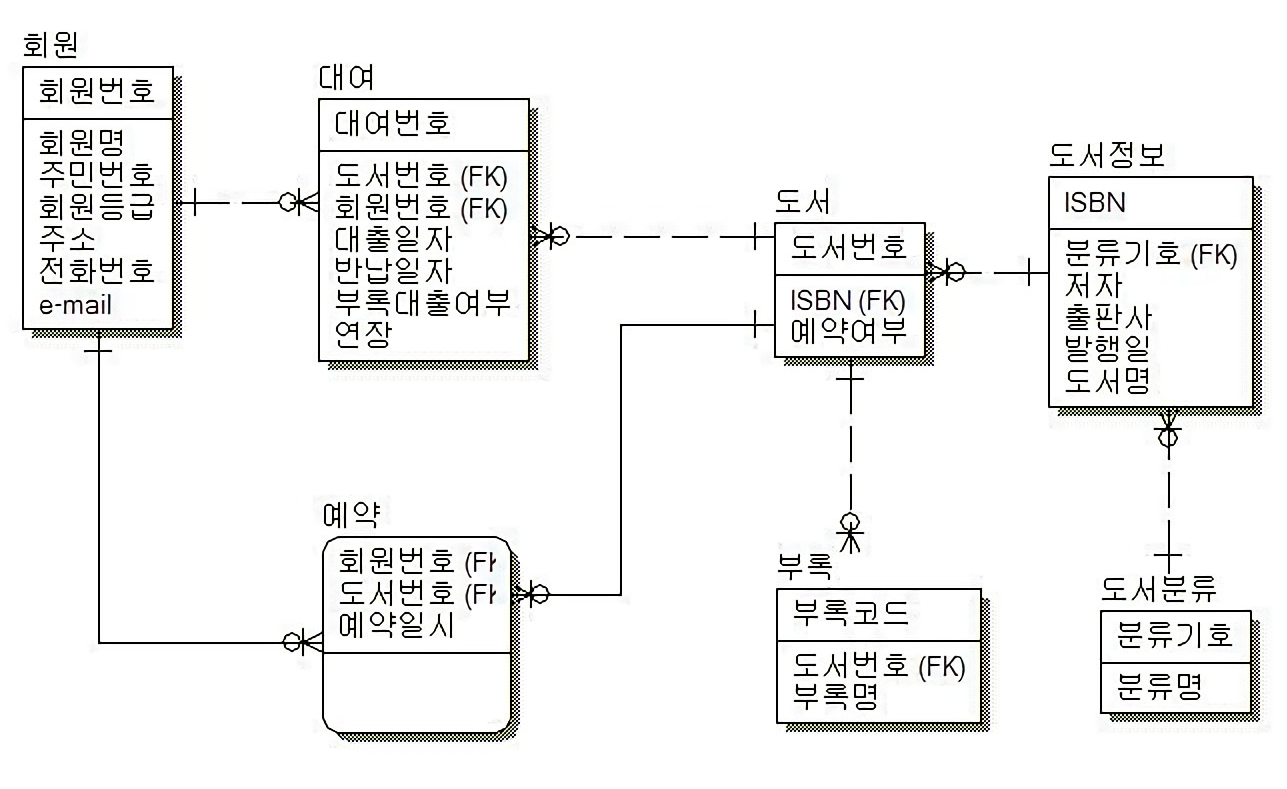
[도서 정보 ↔ 도서]
- ISBN(국제표준도서번호) PK가 도서 테이블에서 FK로 일반속성으로 쓰이고 있다. ( 점선 )
- 같은 책이 여러개 있을 수 있다. 도서정보가 같은 도서가 여러개. ( 1:N )
- 유실된 책이 있을수 있다. 도서정보는 무형의 정보일 뿐이고, 도서 엔티티는 실제 물리적 엔티티이다. ( 1:N[선택] )
- 도서는 반드시 도서 정보가 필수로 존재해야한다. ( 1[필수]:N[선택] )
[도서 ↔ 예약]
- 도서번호 PK가 예약 테이블에서 FK이자 PK로 쓰이고 있다. ( 실선 )
- 하나의 도서에 여러개 예약이 걸려 있을수 있다. ( 1:N )
- 예약이 없는 도서가 있을 수 있다. ( 1:N[선택] )
- 예약 정보에는 반드시 도서 정보가 들어 있어야 한다. ( 1[필수]:N[선택] )
ERD 다이어그램 툴 추천
손그림으로 ERD 다이어그램을 그리지말고 소프트웨어를 빌려 짜임새 있게 구성하는 것이 나중에 유지보수 할때 유용하다. 이 포스팅에서는 대표적인 ERD 다이어그램 툴 두가지를 소개해본다.
MySQL 워크벤치에서 ERD 만들기
- 워크벤치 자체에 ERD 다이어그램 툴이 내장되어 있다.
- 미리 작성된 SQL문을 자동으로 ERD로 바꿔주기도 하여 유용하다.
[MYSQL] 📚 워크벤치에서 테이블 ERD 생성하기 / 쿼리 추출하기
MySQL 워크벤치 ERD 생성 1. 상단 메뉴 탭에서 Database > Reserve Engineer를 선택한다. 2. Hostname, port, username을 입력하고 다음으로 이동한다. 3. ERD로 추출할 DB를 선택 후 다음으로 이동한다. 4. R..
inpa.tistory.com
온라인에서 ERD 만들기
- 워크벤치는 좀 오래된 소프트웨어라서 보기에도 올드하고 가독성도 그렇게 좋지 않다.
- 온라인 사이트에서 보다 자세하게 ERD를 그리고, 쿼리를 추출할수 있으며 협업도 가능한 ERD CLOUD를 강력 추천하는 바다.
[ERD CLOUD] ☁️ ERD 다이어그램을 온라인에서 그려보자
ERD CLOUD 프론트엔드 작업을 하기전에 UI 와이어프레임을 그리는 과정은 중요하듯이, 백엔드에서도 데이터베이스 모델링 설계 과정은 매우 중요하다. 데이터베이스 모델링을 할 때 ERD 다이어그
inpa.tistory.com
# 참고자료
쉽게 배우는 오라클로 배우는 데이터베이스 개론과 실습
https://dba.stackexchange.com/questions/51073/er-relation-with-unique-key
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=lkwook2&logNo=100116488273
https://parkhyeokjin.github.io/others/2018/11/07/DbERD.html
https://blog.naver.com/PostView.nhn?blogId=dodnam&logNo=221750031014&parentCategoryNo=&categoryNo=17&viewDate=&isShowPopularPosts=true&from=search
이 글이 좋으셨다면 구독 & 좋아요
여러분의 구독과 좋아요는
저자에게 큰 힘이 됩니다.


