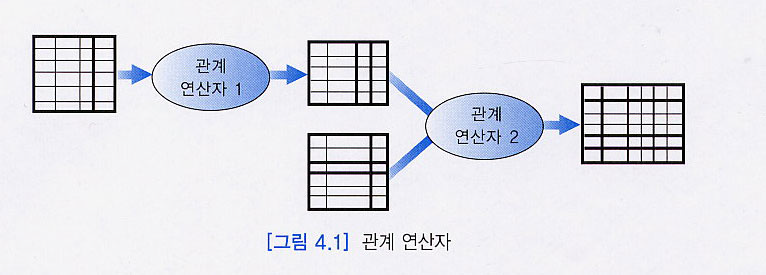
관계 대수식이란 기존 릴레이션(테이블)들로부터 새로운 릴레이션을 생성하는 절차적 언어 문법이라고 보면 된다. 릴레이션에 대해 기본적인 연산자들을 적용하여 보다 복잡한 관계 대수식을 점차적으로 만들 수 있다.
쉽게 생각해 우리가 숫자를 더하거나 나누어 원하는 수를 도출하듯이, 릴레이션을 관계 대수라는 전용 연산자를 통해 더하거나 곱해 원하는 릴레이션을 도출하는 것으로 생각하면 된다.
관계연산자들은 릴레이션의 특성에 따라 일반 집합 연산과 순수 관계 연산으로 나뉘며, 각각의 연산 결과는 또 다른 관계 대수식의 입력으로 사용될 수 있다.
이렇게 관계 대수식은 사용자가 원하는 데이터를 얻기 위한 절차를 시스템에 명세하는 데이터 언어로서 관계 데이터 모델에서의 릴레이션을 조작하기 위한 기본 연산 중 하나이다. 그래서 관계 대수는 상용 관계 DBMS들에서 널리 사용되는 SQL의 이론적인 기초이기도 하다. 또한 SQL을 구현하고 최적화하기 위해 DBMS의 내부 언어로서도 사용된다.
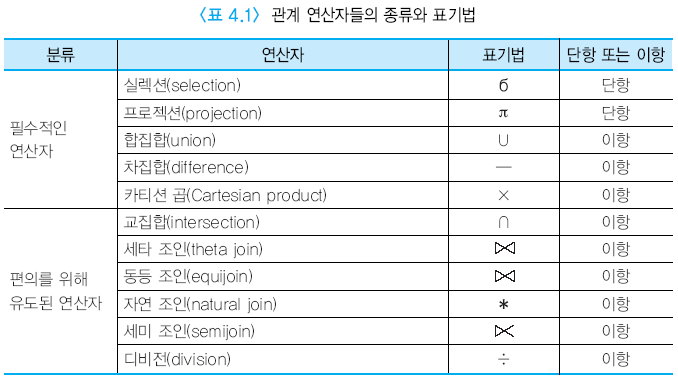
관계 대수의 8대 연산자
8대 관계 연산자란, 관계형 데이터베이스에서 자주 사용되는 8가지 기본적인 연산자들을 의미한다. 이러한 연산자들은 데이터베이스의 기초적인 연산들이며, 관계형 데이터베이스에서 매우 중요한 개념이다. 관계 연산자들을 잘 이해하고 사용함으로써, 데이터베이스의 질의를 보다 효율적으로 수행할 수 있기 때문이다.
셀렉션 : 테이블에서 한 개 끄집어낸다
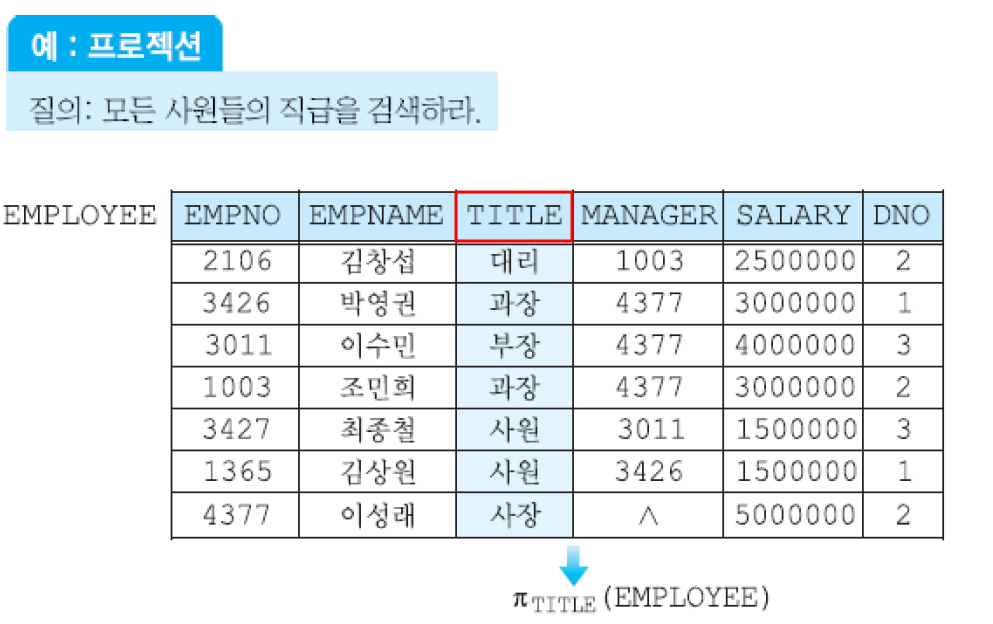
프로젝션 : 학생 테이블에서 특정한 학번 이름만 출력.
합집합 : union 겹치는 걸 제외하고 테이블 합
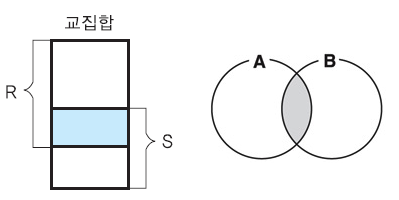
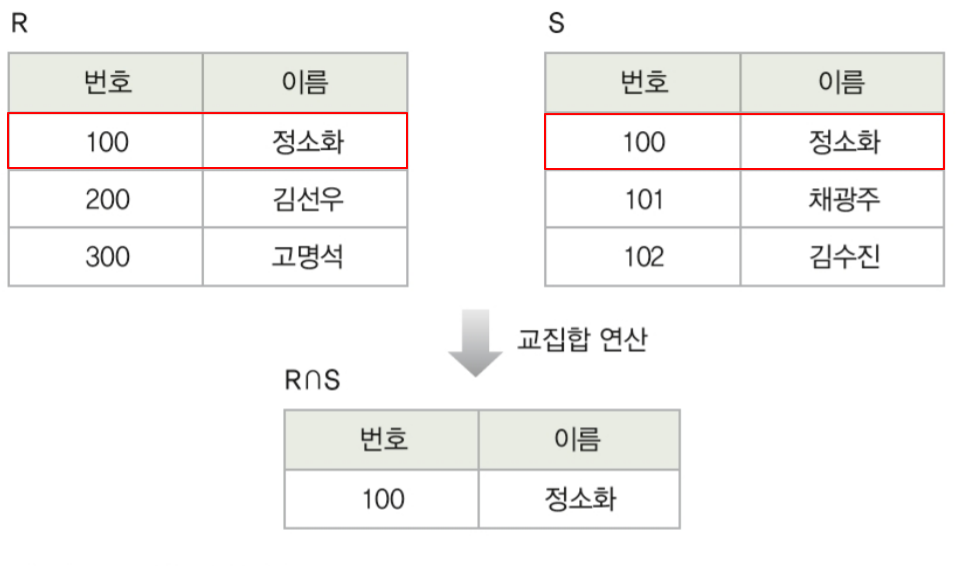
교집합 : 겹치는 것만 테이블
차집합 : A - B 한 결과 테이블
카티션 곱 : 나올수 있는 조합 경우의 수
조인 : 결합
디비전 : 분할
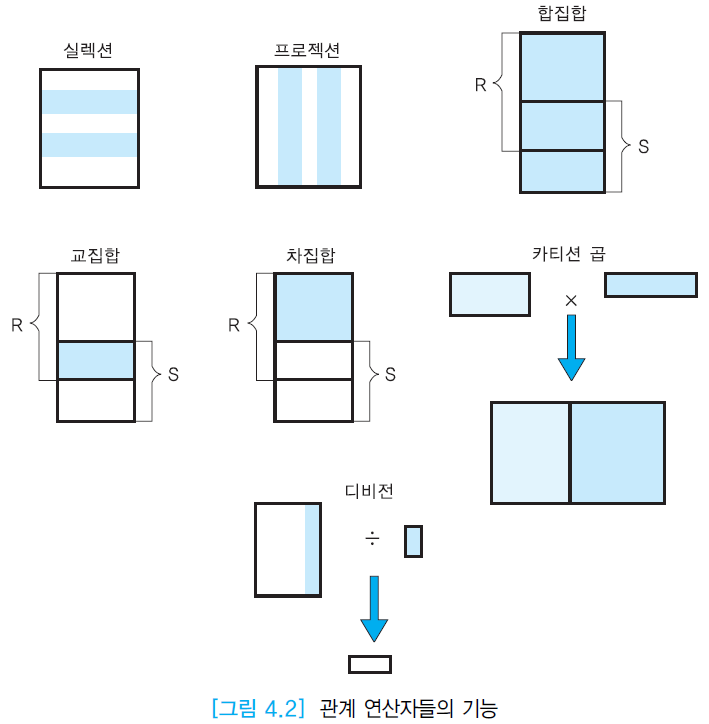
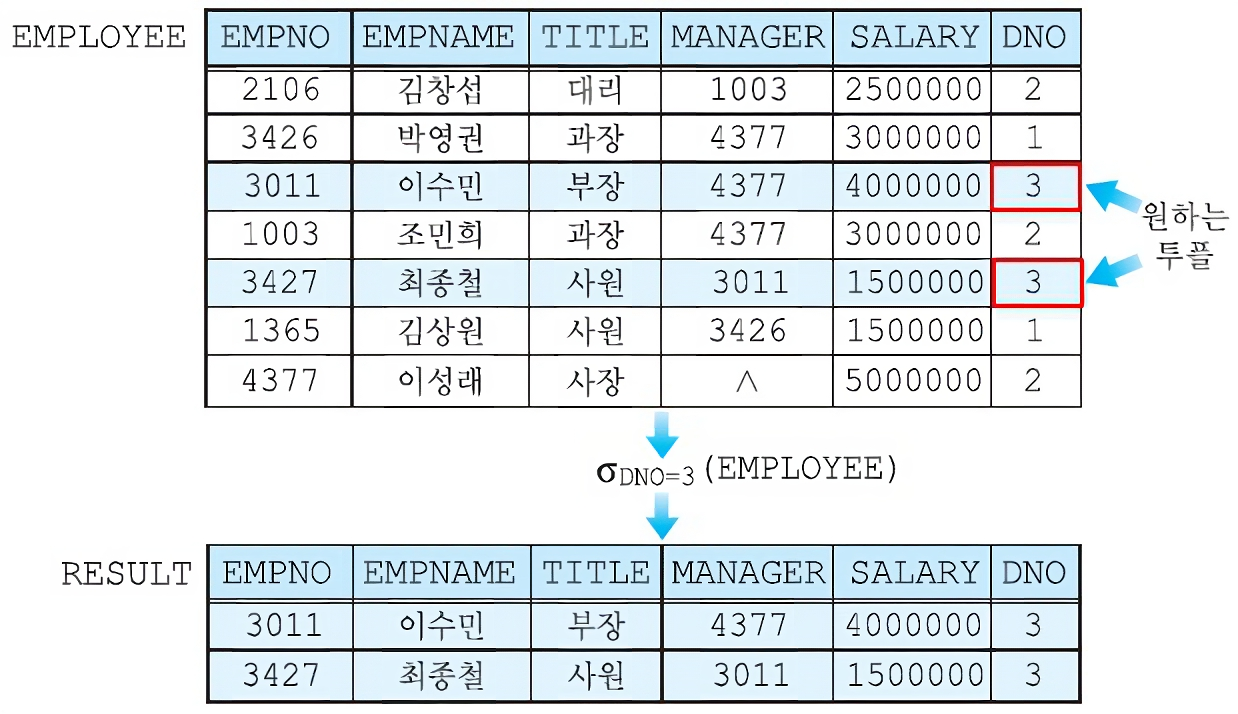
셀렉션 연산자 σ
원하는 데이터를 수평적으로 도출함
σ (sigma)로 연산자를 표현
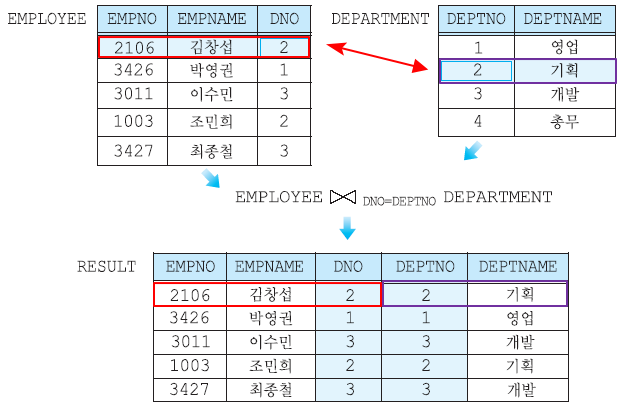
σ DNO=3 (EMPLOYEE) : EMPLOYEE 테이블에서 DNO가 3인 행을 도출
프로젝션 연산자 Π
원하는 데이터를 수직적으로 도출함
Π (pi)로 연산자를 표현
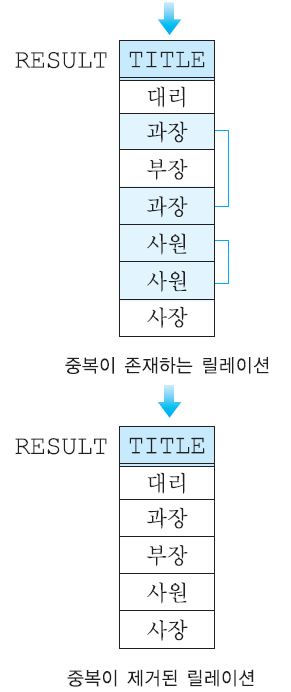
보통 셀렉션의 결과 릴레이션에는 중복 튜플이 존재할 수 없지만, 프로젝션 연산의 결과 릴레이션에는 중복된 튜플들이 존재할 수 있다. 따라서 도출된 릴레이션에 중복이 들어있다면 이 중복은 자동으로 제거된다.
Π TITLE(EMPLOYEE) : EMPLOYEE 테이블에서 TITLE 열을 도출
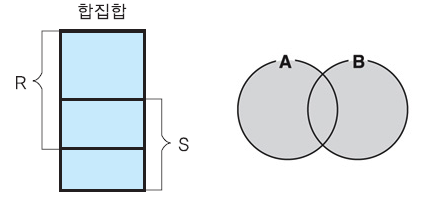
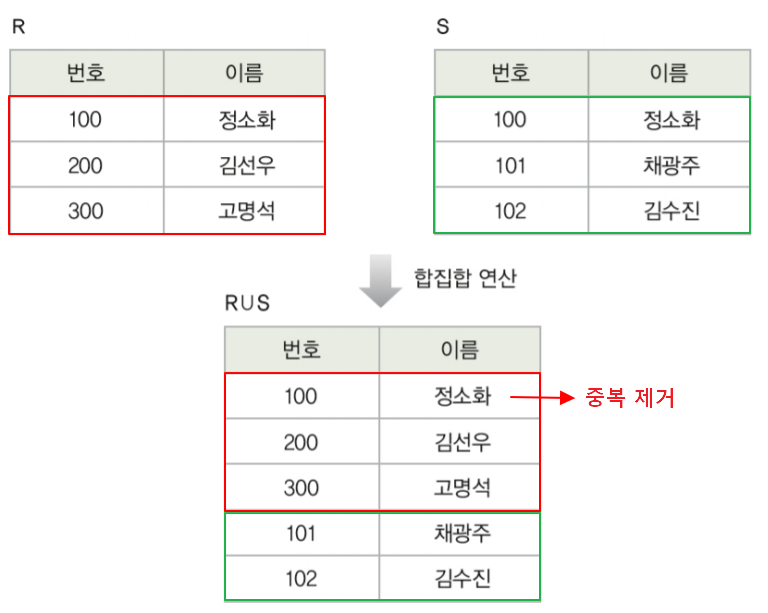
합집합 연산자 ∪
두 릴레이션의 튜플들을 합침
합친 결과 릴레이션에서 중복된 투플들은 제외됨
∪ 로 연산자를 표현
합집합은 합집합 호환 조건이 맞아야만 실행할 수 있다.
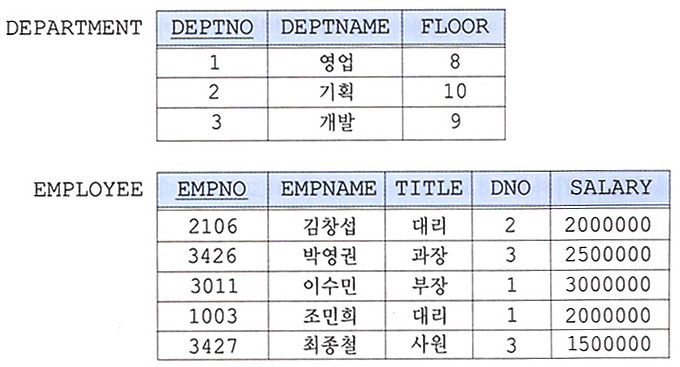
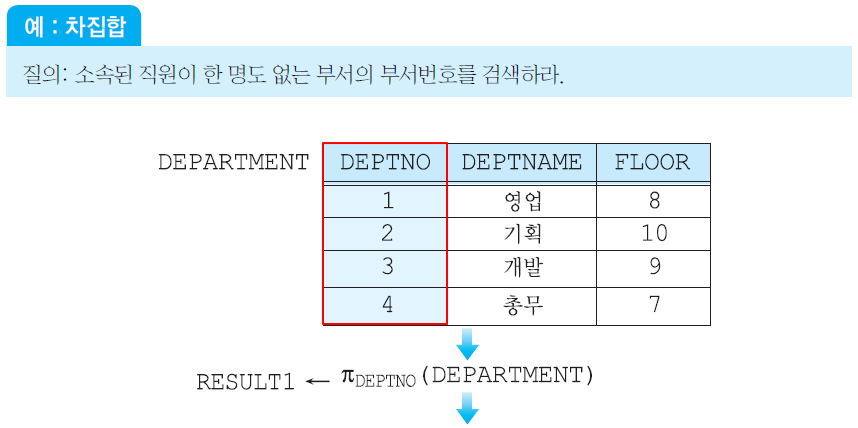
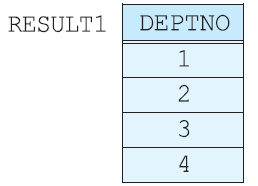
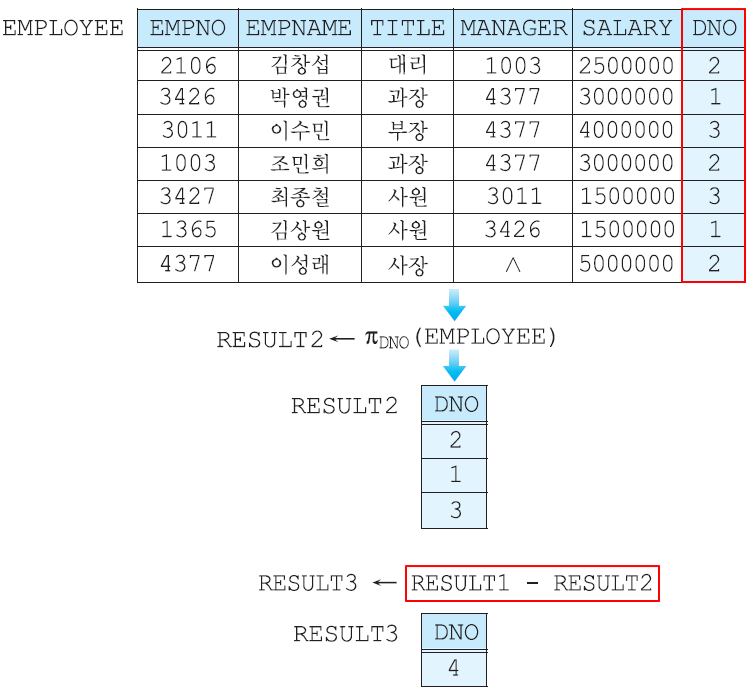
합집합 호환 (union compatible) 서로 다른 테이블에 union 하는데 있어, 갯수가 다르거나 도메인이 다르면 안된다. 이 규칙은 합집합, 차집합, 교집합에 모두 적용된다. 예를들어, 아래의 EMPLOYEE 릴레이션과 DEPARTMENT 릴레이션은 기본적으로 어트리뷰트 수가 다르므로 합집합 호환 조건에 맞지 않는다고 생각할 수 있다.
그러나 EMPLOYEE 릴레이션에서 DNO를 프로젝션한 결과 릴레이션과 DEPARTMENT 관계에서 DEPTNO를 프로젝션한 결과 릴레이션은 애트리뷰트수가 같으며DEPTNO와DNO 도메인이 같기 때문에, 따라서 두 릴레이션은 결과적으로 합집합 호환 조건이 부합된다.
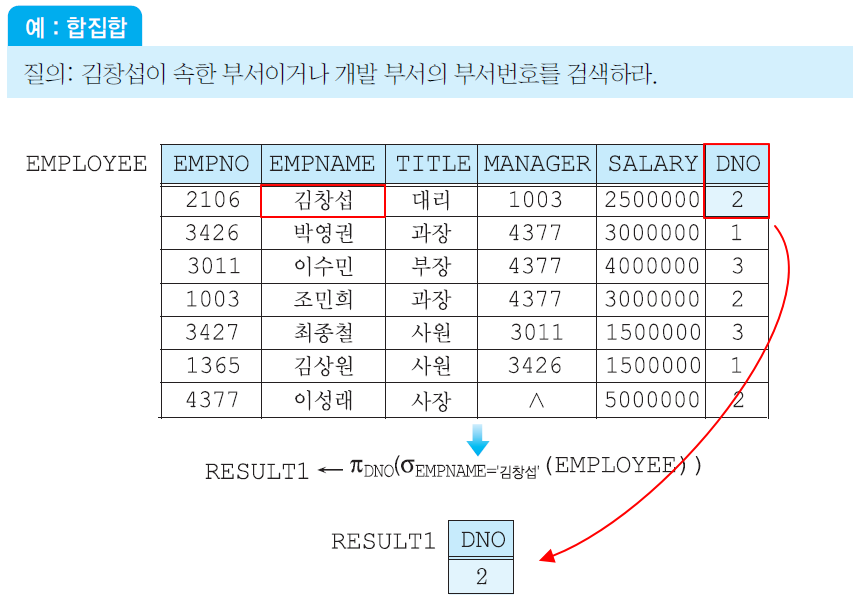
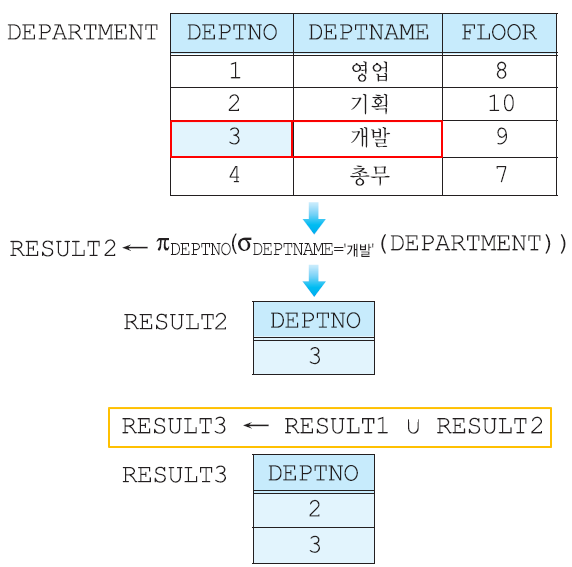
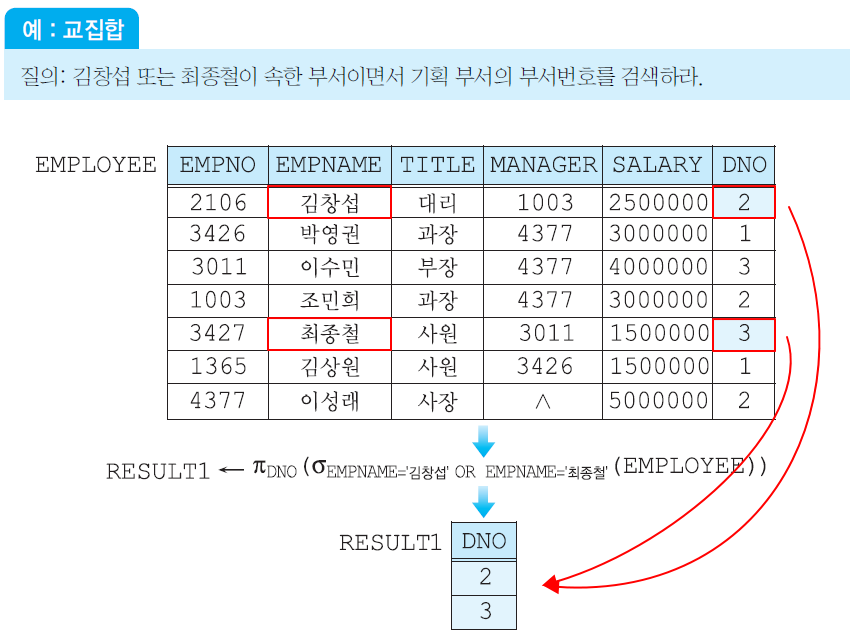
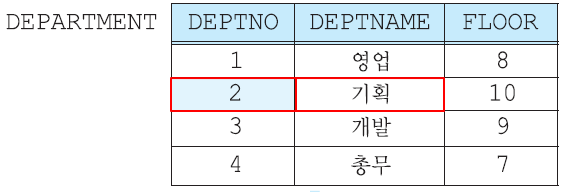
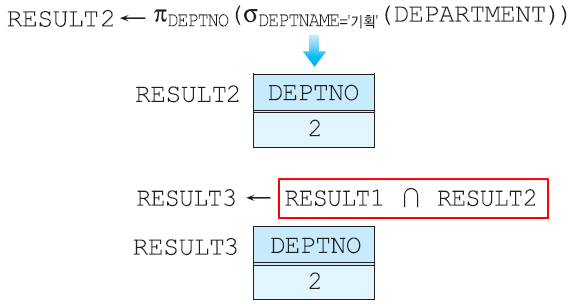
김창섭이 속한 부서의 부서번호 + 개발 부서의 부서번호
교집합 연산자 ∩
두 릴레이션의 튜플들의 겹치는 부분만을 도출
∩로 연산자를 표현
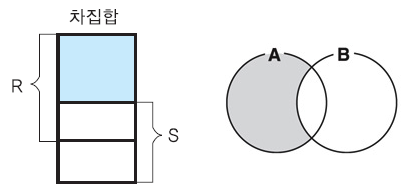
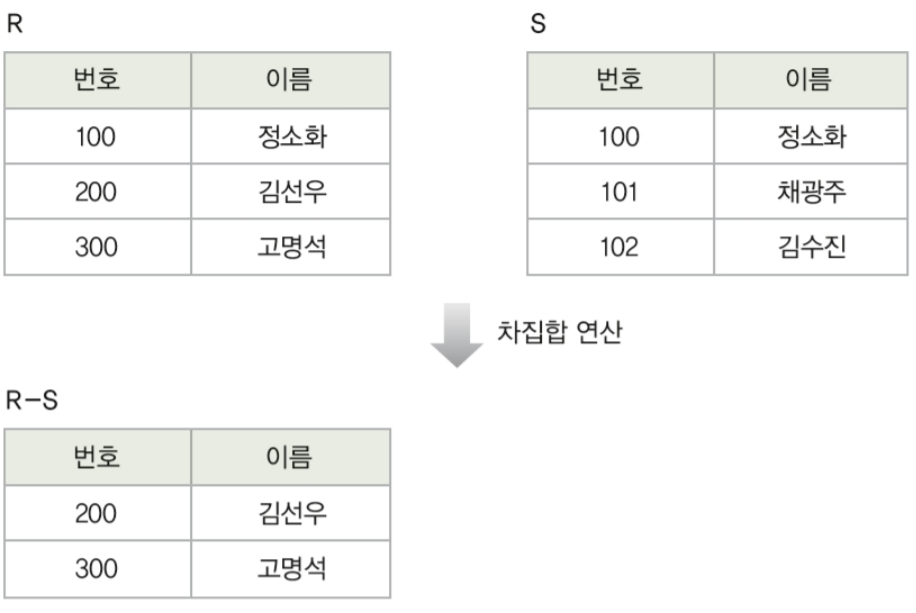
차집합 연산자 -
두 릴레이션의 튜플들의 겹치지 않는 부분만을 도출
-로 연산자를 표현
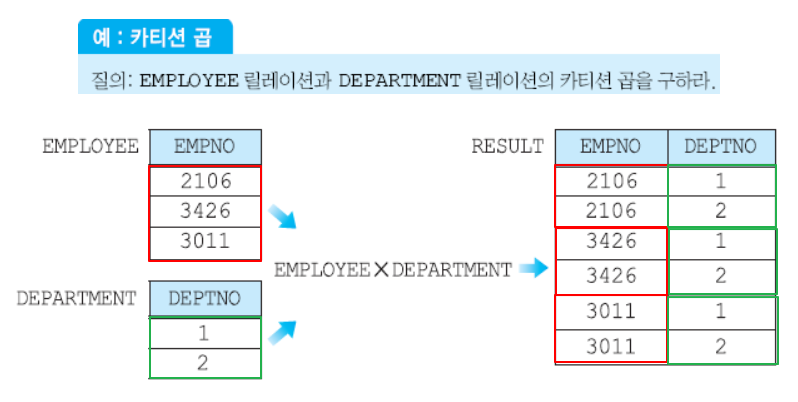
카티션 곱 연산자 ×
두 릴레이션(테이블) 에서 가능한 모든 조합을 만들어주는 연산자
두 테이블로 만들 수 있는 모든 경우의 수를 나타내는 전체 집합을 도출
카디션 곱해서 나오는게 값이 크면 오버헤드가 너무 커지기 때문에 실제로는 카티션 곱 연산자는 사용하지않고 뒤에서 배울 조인(join) 연산자를 사용한다.
×로 연산자를 표현
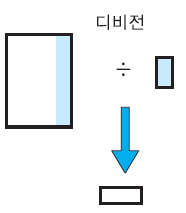
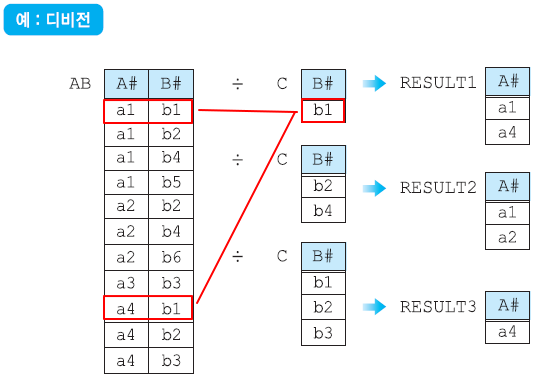
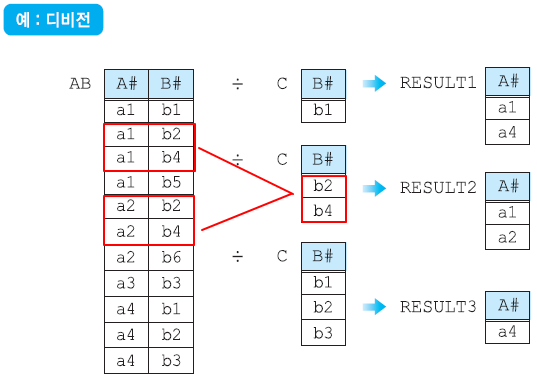
디비전 연산자 ÷
한 테이블에서 다른 테이블의 모든 값을 가지고 있는 행들을 찾아주는 연산자
'모든 ~에 대해 ~하는' 형태의 질의에 사용될 수 있음
디비전은 나누는 테이블의 열의 개수만큼 결과 테이블의 열의 개수가 줄어들게 된다
÷로 연산자를 표현
조인 연산자 ⋈
두 개의 릴레이션으로부터연관된 투플들을 결합하는 연산자
⋈로 연산자를 표현
조인 연산자는 다음과 같이 연산 방식에 따라 여러 조인으로 나뉜다
세타 조인(theta join)
동등 조인(equi join)
자연 조인(natural join)
외부 조인(outer join)
세미 조인(semi join)
세타 조인 & 동등 조인
세타 조인은 두 릴레이션에서 공통된 애트리뷰트를 기준으로 비교 연산자(=,<>,<=,<,>=,>)를 사용하여 조건을 만족하는 튜플들을 결합하는 것이다.
동등 조인은 세타 조인 중에서 비교 연산자가 =인 조인이다. 즉, 두 릴레이션에서 공통된 애트리뷰트의 값이 같은 튜플들을 결합하는 것을 말한다.
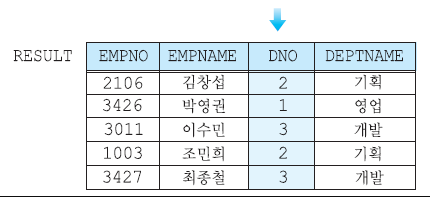
자연 조인
동등 조인의 결과 릴레이션에서 조인 애트리뷰트를 제외한 조인 (중복 필드 제거)
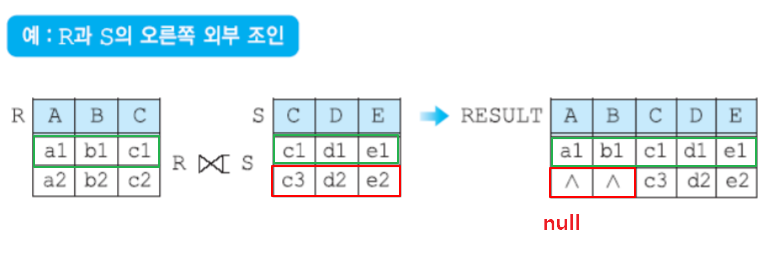
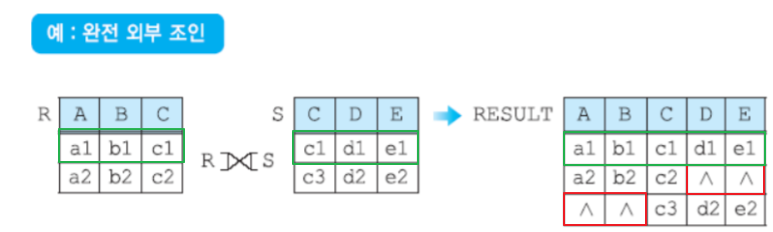
외부 조인
널값이 들어 있는 투플들을 다루기 위해서 조인 연산을 확장한 조인
일반적인 조인은 두 릴레이션에서 대응되는 튜플이 없을 경우, 그 튜플을 결과에 포함시키지 않는다. 하지만 외부 조인은 대응되는 튜플이 없어도 결과에 포함시키고, 상대 릴레이션의 애트리뷰트 값은 null로 채운다.
외부 조인에는 어느 릴레이션을 기준으로 null로 채우는지에 따라 3가지로 나뉜다.
왼쪽 외부 조인(left outer join)
오른쪽 외부 조인(right outer join)
완전 외부 조인(full outer join)
left outer joinright outer joinfull outer join
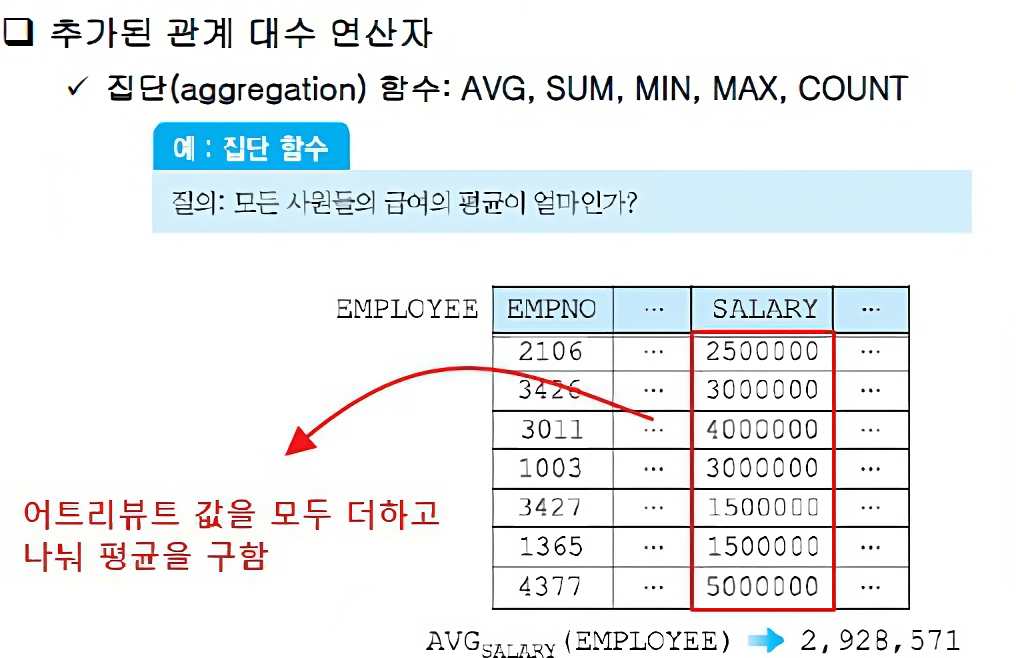
집단 함수
한 릴레이션에서 특정 속성들의 값들에 대해 총합, 평균, 최대, 최소, 개수 등의 연산을 수행하는 함수
관계 대수의 표현력을 높이기 위해 새로 추가된 연산자
집단 함수는 각 그룹에 대해 독립적으로 적용되며, 그룹화 연산자와 함께 사용 된다.
AVG, SUM, MIN, MAX, COUNT
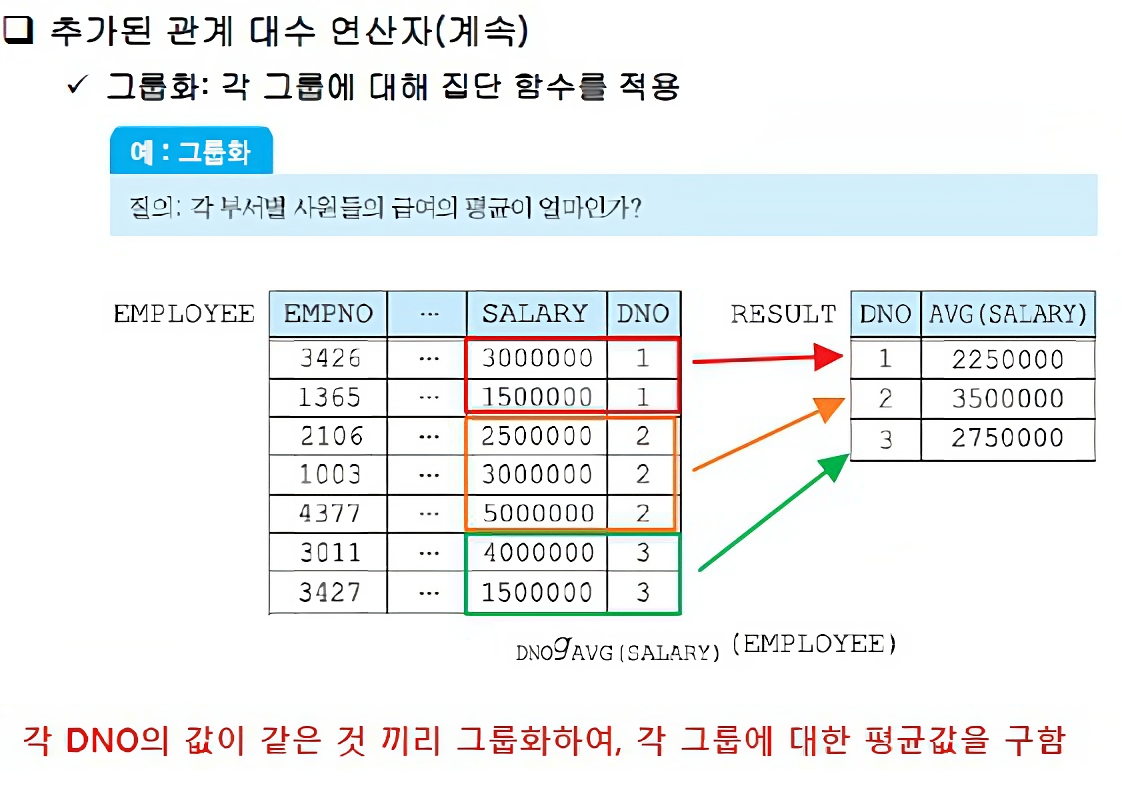
그룹화
한 릴레이션에서 특정 속성들의 값에 따라 튜플들을 여러 그룹으로 분류하고, 각 그룹에 대해 집단 함수를 적용하는 연산자
그룹화 연산자는 G로 표기됨
관계 대수와 SQL
관계 대수는 관계 데이터베이스에서 릴레이션을 조작하기 위한 절차적 언어이다. 즉, 원하는 데이터를 얻기 위해 어떤 연산을 어떤 순서로 수행할 것인지를 수학 공식 처럼 명시함으로써 릴레이션을 도출 할 수 있다. 관계 대수에는 일반 집합 연산자와 순수 관계 연산자가 있으며, 이들은 모두 릴레이션을 입력으로 받아 릴레이션을 출력한다. SQL은 관계 데이터베이스에서 데이터를 정의하고 조작하기 위한 선언적 언어이다. 즉, 원하는 데이터가 무엇인지만 선언하면 데이터베이스 시스템이 알아서 최적의 방법으로 질의를 수행한다. SQL에는 DDL(Data Definition Language), DML(Data Manipulation Language), DCL(Data Control Language) 등의 구성 요소가 있으며, 이들은 모두 릴레이션에 대한 연산을 표현이다.
관계 대수와 SQL은 서로 밀접한 관계에 있다고 볼 수 있다. 애초에 관계 대수의 업그레이드 버전이 SQL 이기 때문이다. SQL은 관계 대수의 한계를 극복하고, 관계 데이터베이스에서 다양한 데이터를 쉽고 강력하게 조작할 수 있도록 해준다. 아주 쉽게 비유하자면, 수학 공식과 같은 관계 대수식을 프로그래밍 언어처럼 구성한게 SQL이라고 보면 된다.
예를 들어, 관계 대수의 셀렉트 연산자는 SQL의 WHERE 절과 대응되고, 프로젝트 연산자는 SQL의 SELECT 절과 대응된다. 또한, 관계 대수의 조인 연산자는 SQL의 JOIN 절과 대응되며, 집단 함수와 그룹화 연산자는 SQL의 집합 함수와 GROUP BY 절과 대응된다.
-- 셀렉트 연산자: σ<salary > 3000000> (EMP)
SELECT * FROM EMP WHERE salary > 3000000;
-- 프로젝트 연산자: Π<name, dept> (EMP)
SELECT name, dept FROM EMP;
-- 합집합 연산자: EMP ∪ MANAGER
SELECT * FROM EMP UNION SELECT * FROM MANAGER;
-- 교집합 연산자: EMP ∩ MANAGER
SELECT * FROM EMP INTERSECT SELECT * FROM MANAGER;
-- 차집합 연산자: EMP - MANAGER
SELECT * FROM EMP EXCEPT SELECT * FROM MANAGER;
-- 카티션 곱 연산자: EMP × DEPT
SELECT * FROM EMP CROSS JOIN DEPT;
-- 조인 연산자: EMP ⋈<EMP.dept = DEPT.dno> DEPT
SELECT * FROM EMP JOIN DEPT ON EMP.dept = DEPT.dno;
-- 디비전 연산자: WORKS ÷ PROJECT
SELECT empno FROM WORKS GROUP BY empno HAVING COUNT(*) = (SELECT COUNT(*) FROM PROJECT);
-- 집단 함수와 그룹화 연산자: DNO G AVG_SALARY (EMP)
SELECT DNO, AVG(SALARY) AS AVG_SALARY FROM EMP GROUP BY DNO;
따라서, SQL 언어를 학습하기 앞서 먼저 관계 대수를 이해하면 릴레이션 도출 원리는 거의 같으니 단순히 SQL 문법만 추가로 배우면 이미 데이터베이스 테이블을 다루는데 문제가 없다. 물론 처음부터 SQL을 통해 관계 대수의 개념과 원리를 학습할 수도 있다.
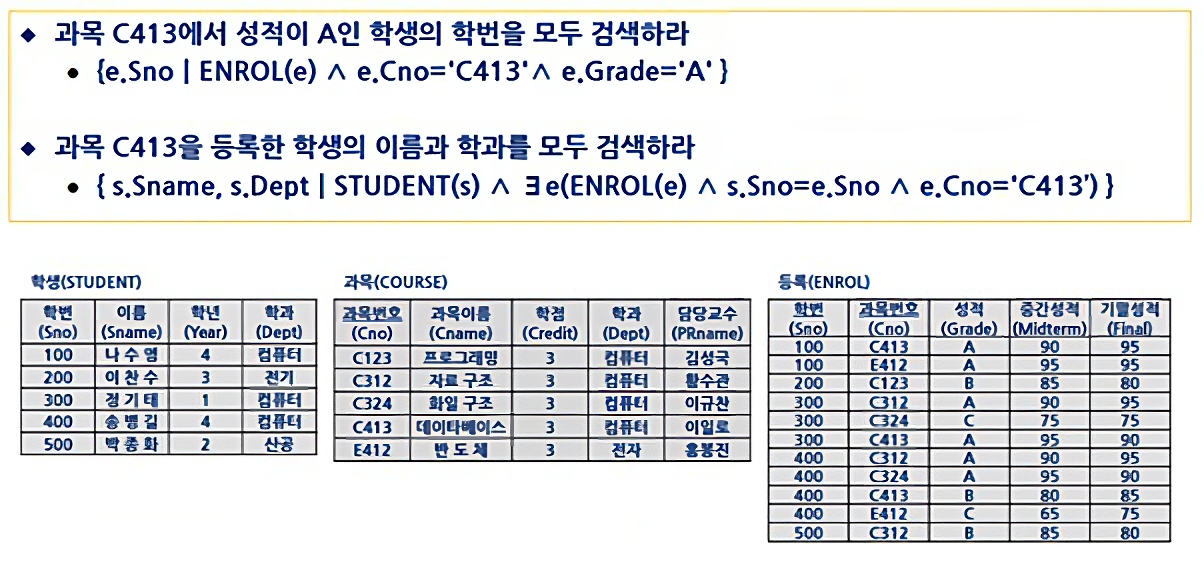
관계 해석 (Relation Calculus)
우리가 지금까지 배운 관계 대수는 전용 연산자를 통해 원하는 목표 데이터를 얻기 위하여 어떻게 데이터를 검색할 것인지 절차를 수학 식으로 순차적으로 명세해 릴레이션을 도출해왔다.
반면, 관계 해석은 원하는 데이터가 무엇인지만 선언하는 이른바 비절차적 언어이다. 즉, 원하는 데이터만 명시하고 "어떻게 질의를 해석하는가"에 대해 언급이 없는 선언만 하는 언어인 것이다.
관계 해석은 튜플 관계 해석 (Tuple Relational Calculus),도메인 관계 해석 (Domain Relational Calculus) 종류가 있으며, 수학 식 형태로는 아래와 같다.
-- EMPLOYEE 릴레이션에서 급여가 3000 이상인 사원들의 이름과 급여를 찾는 관계 해석 식
{<t.Ename, t.Salary> | t ∈ EMPLOYEE ∧ t.Salary ≥ 3000}
-- 위의 관계 해석식과 매칭되는 SQL 코드
SELECT Ename, Salary
FROM EMPLOYEE
WHERE Salary >= 3000;
구분
구성요소
기호
설명
연산자
OR 연산
V
원자식 간 “또는”이라는 관계로 연결
AND 연산
∧
원자식 간 “그리고”라는 관계로 연결
NOT 연산
ㄱ
원자식에 대해부정
정량자
전칭 정량자 (Universal Quantifier
∀
모든 가능한 튜플 “For All” # All의 ‘A’를 뒤집은 형
존재 정량자 (Existential Quantifier)
∃
어떤 튜플 하나라도 존재 “There Exists” # Exists의 ‘E’를 뒤집은 형
관계 대수식과 완전히 다른 관계 해석식을 보니 머리만 아프다
관계 대수 vs 관계 해석
관계대수는 어떻게 데이터를 처리할지를 효율적으로 정하는 데 사용되며, 관계해석은 어떤 데이터가 필요한지를 더욱 간단하게 정의하는 데 사용된다고 보면 된다.
관계대수
관계해석
절차적 언어(순서 명시)
비절차적 언어(계산 수식의 유연적 사용), 프레디킷 해석(Predicate Calculus) 기반
원하는 정보를 얻기 위해 어떻게 (how) 질의를 해석하는지를 기술
원하는 정보가 무엇 (what) 인지만 명시하고 어떻게 질의를 해석하는지에 대해 언급하지 않는 선언
연산자와 피연산자로 구성되며, 연산자는 릴레이션에 적용되어 새로운 릴레이션을 생성
명제와 변수로 구성되며, 명제는 참 또는 거짓의 값을 가지고, 변수는 릴레이션의 튜플이나 애트리뷰트 값을 나타냄
연산자의 종류에 따라 다양한 데이터 조작을 할 수 있음
연결자와 한정자를 사용하여 복잡한 조건식을 만들 수 있음
종류로는 순수관계 연산자, 일반집합 연산자가 있다
종류로는튜플 관계 해석, 도메인 관계 해석이 있다
관계 해석을 반드시 공부해야 되는가 🤔
보통 대학 강의나 데이터베이스 교제를 보면, 관계 대수에 대해 자세히 다루고 바로 SQL로 넘어가지, 관계 해석을 중점적으로 다루지는 않는다. 관계 대수로 릴레이션 조합법 및 도출 원리를 배우고 바로 SQL로 실전 데이터베이스 질의를 습득하는 것 만으로도 실무를 하는데 충분하기 때문이다.
애초에 관계 해석은 비절차적인 언어이기 때문에, 컴퓨터가 직접 실행할 수 있는 형태가 아니다. 그래서 관계 해석으로 표현된 질의를 관계 대수로 변환하거나 SQL로 번역해야 하는 추가 작업이 든다. 따라서 데이터베이스 관련 서적에서는 관계 대수에 대해 자세히 다루고 관계 해석은 간단하게 다루는 경우가 많다. 하지만 이것은 관계 해석이 중요하지 않다는 의미가 아니라, 관계 대수가 실제 데이터베이스 시스템에서 더 많이 사용되고 구현하기 쉽기 때문이다.
관계 해석을 공부하면 데이터베이스의 이론적인 배경과 논리적인 구조를 이해할 수 있고, SQL을 보다 효과적으로 작성하고 분석할 수 있다. 또한 관계 해석은 데이터베이스의 의미와 제약 조건을 명확하게 표현할 수 있는 방법이므로, 데이터베이스 설계와 모델링에도 도움이 된다. 실제로 관계 해석은 관계 대수와 동등한 표현력을 가지고 있으며, 논리적인 추론과 수학적인 표현을 사용하여 질의를 정의할 수 있다. 따라서 관계 해석은 데이터베이스에 대한 깊은 지식과 실력을 향상시키는 데 유용하다.
그러나 아무래도 관계 대수, 관계 해석을 모두 공부하기에는 시간적인 여유 때문에 현실적으로는 힘든것은 사실이다. 그래서 관계 대수를 우선적으로 공부하고, 관계 해석은 필요한 부분만 공부하는 것도 나쁘지 않다. 중요한 것은 데이터베이스의 이론과 SQL을 통해 데이터베이스 실습을 병행하면서 데이터베이스에 대한 깊은 지식과 실력을 향상시키는 것이다.